고정 헤더 영역
상세 컨텐츠
본문
instance segmentation 은 이미지 내에 존재하는 모든 객체를 탐지하여, 각각의 instance를 픽셀단위로 classification(분류)하는 task이다.
Mask R-CNN은 이런 image instance segmentation model이다.
Mask R-CNN은 Faster R-CNN에 Mask branch를 더한 구조이다.
Mask Branch에서는 object의 mask를 예측하는 역할을 한다.
1.Introduction
instance segmentation을 하기 위해서는 두가지의 목표를 달성해야한다.
첫번째로, object detection이 있다. 이는 각각의 객체를 구분하고, BBox를 찾아내는 것이 목표이다.
두번째는, semantic segmentation이다. 이는 객체의 instance를 픽셀단위로, class를 기준으로 분류하는, mask를 찾는 것이 목표다.
Mask R-CNN은 Faster R-CNN에서 각 ROI에 대한 segmentation mask를 예측하는 branch를 확장한 모델이다.
(기존의 Faster R-cnn에서는 분류와 bbox 회귀 branch를 그대로 가져간다.)

mask를 예측하는 branch는 작은 크기의 FCN으로 pixel to pixel 방식으로 픽셀별로 클래스 각각에 대해 물체가 있는지 없는지를 판단하는 segmentation mask를 예측한다.
기존의 Faster R-cnn의 경우 ROI pooling을 사용했는데, 이를 대체하여 mask RCNN에서는 ROI Align을 사용하였다.
이로 인해 Pooling을 통해 발생 되었던, quantized problem을 해결하여 위치 정보를 보존 할 수 있었다.
(Feature map의 ROI의 size가 딱 나눠떨어지지 않은 현상)
그리고 이전 모델들과 다르게 segmentation mask와 class 예측 과정이 독립적으로 일어나서, 더 좋은 결과를 얻을 수 있었다.(decouple)
2.Mask R-CNN
2.1 Mask R-CNN
<Mask R-CNN 구조>
- stage 1 : RPN(Region Proposal Network)
- stage 2 : Predict the class, box offset and a binary mask for each ROI
<Loss Function>

- Multi-task loss
- total loss = Loss_class + Loss_box + Loss_mask
위 수식에서 class, box, mask가 독립적으로 계산된다.
-> L_mask가 L_class에 영향을 주지 않음
- Loss_mask : (class 갯수) x m x m (m : 이미지 해상도), average binary cross-entropy loss사용
- Semantic Segmentation의 경우, 픽셀마다 class와 mask를 예측함 -> 과한 연산량
본 연구는 class 와 mask 예측이 독립적으로 이뤄지기에 연산 절약 가능
2.2 Mask Representation
Mask : input obj의 spatial layout의 encode 결과
class, box 정보들은 FC layer에 의해 고정된 vector로 변환되기 때문에 공간적 정보 손실이 발생
mask의 경우 FCN(Fully Convolution Network)로 공간적 정보 손실을 최소화 할 수 있다.

FCN을 사용해 각 ROI에서 m x m 크기의 mask를 예측할 수 있다.
FC layer에 의해 1차원 벡터로 축소되지 않고, m x m 형태로 공간 정보 유지 가능, FC lyaer 보다 더 적은 파라미터 수가 사용되어, 연산 속도가 빠르고 정확함
Mask 정보를 mxm형태로 보존하기 위해선, ROI Feature가 필요하다 => ROI Align layer
2.3 ROI Align
- Segmentation 에서 ROI Pooling의 문제점

feature map의 ROI의 size가 딱 나눠 떨어지지 않는 현상 발생 -> quantized (실수 -> 정수형 변환)처리
ROI pooling을 할 때에도 고정된 size(7x7)로 맞춰줘야하기 때문에 또다시 quantized 처리 필요
필연적으로 ROI에 대한 정보 손실이 발생!

균등하게 grid를 나눌 수 없다! -> 정확한 영역을 추정하는데 문제가 발생하게 된다.
- ROI Align with Bilinear Interpolation

<ROI Align>
1. ROI 를 소수점 그대로 매핑
2. ROI의 개별 grid에 4개의 point를 균등하게 배열
3. 개별 point에서 가장 가까운 feature map grid를 고려하면서 point를 weighted sum으로 계산
4. 계산된 point를 기반으로 max pooling


<ROI Align>
1. ROI의 개별 Grid에 4개의 point를 균등하게 배열
2. 주변 feature map gird의 중심점들 찾기(4개)
3. 2번의 인접 중심점들을 이용해 1번 pointer 값에 대한 bilinear interpolation 진행
4. 1번의 4개 pointer들에 대해 max pooling
2.4 Network Architecture
Mask R-CNN은 이미지의 feature를 추출하기 위해 ResNet과 ResNeXt의 50, 101 layer와 FPN(Feature pyramid Network)을 backbone으로 사용했다.

위 아키텍쳐는 Bounding box Recognition(classification + Regression)과 Mask Prediction을 위해 사용된다.
위 두케이스 모두 Faster RCNN head에 mask branch 가 추가된 것을 확인할 수 있다.
backbone의 종류에 따라 head의 구조가 달라지는 걸 볼 수 있다.
2.5 Implementation details
-Training-
- Loss_mask는 오직 Positive ROI에 의해 정의 된다. (Positive ROI : GT와 IoU가 0.5이상)
- 이미지는 800 픽셀로 resized
- 미니 배치에 2장의 이미지 사용,각 이미지에 N개의 샘플링 된 ROi 있음
- GPU : 8개, mini batch size :16, iter : 160k, lr : 0.02 => 10~120k동안 학습률 감소
- ResNeXt에서는 GPU하나당 한개의 이미지, lr : 0.01이고 나머진 동일
-Inference-
- Resnet은 proposal 갯수 300개, FPN은 100개
- box prediction 후에 NMS
- Mask branch는 상위 score 100개 box만 => 속도 향상
- Mask branch는 각 ROI마다 class 개수만큼의 mask 예측
4.Experiments: Instance Segmentation
main Results


- Mask R-CNN이 state-of-the-art 모델 보다 훨씬 더 좋은 성능을 보임

- ResNet-101-FPN을 BackBone으로 가지는 Mask R-CNN이 FCIS+++보다 뛰어난 성능을 보였다.
Ablation Experiments
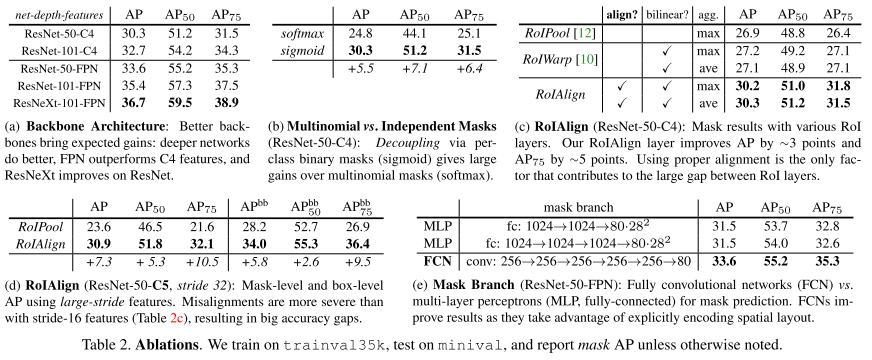
(a) -> mask RCNN에서 deeper일 수록 성능이 좋은 걸 확인할 수 있다.
(b) -> Mask branch를 분리한 sigmoid에서 성능이 더 좋았다.
(c,d) -> ROI align을 통해 성능이 향상되었다.
(e) -> Mask branch에서 MLP를 사용하는 것보다 FCN을 사용하는 것이 성능이 더 좋다.
Bounding Box Detection Results

- Mask output은 무시하고 Mask R-CNN을 기존의 state of the art 모델들과 결과를 비교헀다.
- ResNet-101-FPN을 사용한 Mask R-CNN이 기존의 모델들보다 성능이 좋았다.
5.Mask R-CNN for Human Pose Estimation






댓글 영역