고정 헤더 영역
상세 컨텐츠
본문
Introduction

컴퓨터가 사람처럼 실시간으로 객체 탐지를 하기 위해서는 빠르고 정확한 모델이 필요합니다. 하지만 sliding window approach를 사용하여 이미지 하나를 학습할 때 classification을 여러번 해야 하는 DPM이나 multi pipeline 모델인 R-CNN과 같이 현재 사용되는 객체 탐지 모델들은 느리고 최적화하기 어렵습니다. YOLO(You only look ONCE)는 이름에서 알 수 있듯이 객체 탐지를 하나의 regression problem으로 보아 하나의 신경망이 bounding box와 class 확률값을 예측합니다.
YOLO의 장점은 다음과 같습니다.
1. 매우 빠릅니다. 1초에 45프레임을 처리할 수 있으며, Fast YOLO의 경우에는 1초에 150프레임 이상을 처리할 수 있습니다. 또한 다른 실시간 객체탐지모델의 평균에 비해 mAP가 두 배 이상 높습니다.
2. 예측을 할 때 이미지 전체를 봅니다. sliding window나 위치후보(region proposal-based techniques)를 사용하는 기존 모델들과는 달리, 학습에 있어서 전체 이미지를 보기 때문에 객체의 생김새에 대한 정보뿐만 아니라 객체의 주변에서 추론할 수 있는 contextual information도 학습과 예측에 사용합니다. 때문에 YOLO는 큰 맥락을 보지 못하는 Fast R-CNN에 비하여 background를 객체로 인식하는 오류가 절반 이하로 적습니다.
3. 객체의 일반적인 특징(generalizable representations)을 학습합니다. natural image로 학습을 한 후 artwork에 적용을 했을 때, YOLO는 DPM이나 R-CNN보다 훨씬 좋은 성능을 보여주었습니다. 일반적인 특징을 학습하기 때문에 YOLO는 새로운 도메인에 적용하기 쉽고 예상하지 못한 input에도 비교적 robust합니다.
YOLO는 빠르지만 대신 정확도가 낮다는 단점이 있습니다. 특히 크기가 작은 객체의 경우 정확도가 떨어집니다.
Unified Detection

YOLO는 객체 탐지의 여러 단계를 하나의 신경망으로 통합했습니다. 각 bbox에 대한 예측을 할 때 전체 이미지 feature를 사용하며, 각 bbox마다 모든 class에 대해 예측을 합니다. 이는 YOLO가 예측에 있어서 전체 이미지와 모든 객체에 대한 정보를 활용한다는 것을 의미합니다.
YOLO는 input 이미지를 S x S 사이즈의 grid로 나눕니다. 이때 한 객체의 중심이 grid cell에 포함될 경우, 해당 grid cell은 그 객체를 탐지하는 데에 responsible합니다.
각 grid cell은 B개의 bbox와 B개의 bbox에 대한 confidence score를 예측합니다. 이 confidence score는 해당 bbox에 객체가 있는지와 예측한 bbox가 얼마나 정확한지를 나타냅니다.

객체가 없으면 confidence score가 0이고 객체가 있는 경우 confidence score는 ground truth와 bbox 간의 IOU값이 됩니다.
* Pr(Object)는 sigmoid 함수
각 bbox는 5개의 예측값 x, y, w, h와 confidence score로 구성됩니다. (x, y) 좌표는 bbox의 중심좌표를 나타내며 이는 grid cell 내에서의 상대 위치값(0-1 사이의 값으로 정규)입니다. (w, h) 값은 전체 이미지 내에서의 상대 위치값입니다. confidence score는 앞서 언급한 confidence score를 말합니다.
각 grid cell은 또한 C개의 조건부 class 확률값을 예측합니다.

이는 해당 grid cell에 객체가 포함되어 있다는 조건 하에 객체가 class i일 확률을 말합니다. 주의할 점은 bbox의 개수에 상관없이 하나의 grid cell 당 하나의 class probability set을 예측한다는 것입니다.
테스트 단계에서는 이 조건부 class 확률값에 bbox confidence score를 곱하여 class-specific confidence score를 구합니다. 이 값은 해당 class의 객체가 bbox에 포함되어 있는지와 예측한 bbox가 얼마나 정확한지를 보여줍니다.

class-specific confidence score
따라서 최종 예측값은 S x S x (B*5 + C)의 사이즈를 가지는데, 본 논문에서는 S = 7, B = 2, C = 20(PASCAL VOC 데이터셋 class 개수)을 사용하여 최종 tensor의 사이즈는 7 x 7 x 30 입니다.
Network Design

GoogleNet에서 기본 구조를 가져온 YOLO는 24개의 convolution layer와 2개의 fc layer로 구성되어 있습니다. 다만 GoogleNet처럼 inception module을 사용하는 대신, 차원 감소를 위한 1x1 layer 후에 3x3 conv layer를 사용했습니다.
Fast YOLO의 경우엔 24개 대신 9개의 conv layer를 사용하고 layer 내에 filter를 더 적게 사용했습니다.
Training
ImageNet 1000-class 데이터셋을 사용하여 첫 20개의 conv layer를 pre-traing하였고 average-pooling layer와 fc layer를 연결해주었습니다. 이때 학습에 Darknet 프레임워크를 사용했습니다. 이후 객체 탐지를 수행하기 위해 모델을 변형합니다. 성능을 높이기 위해 4개의 conv layer와 2개의 fc layer를 더해주었고, 세밀한 정보를 추출하기 위해 input 크기를 224 x 224에서 448 x 448로 늘려줍니다.
활성함수로는 마지막 layer의 선형 활성화 함수를 제외하고 나머지 layer에는 모두 leaky ReLU를 적용하였습니다.

Loss는 최적화가 쉬운 오차 제곱합(SSE)를 기반으로 합니다. 다만, localization error와 classification error의 비중을 조절하고 객체가 존재하는 grid cell의 영향을 줄여주기 위해* 각각 Λ_coord와 Λ_noobj를 추가해주었습니다. 본 논문에서는 Λ_coord = 5, Λ_noobj = 0.5를 사용했습니다.
* 객체가 존재하지 않는 grid cell이 더 많으며 해당 cell의 confidence score는 0이 됨. 따라서 객체가 존재하는 cell의 graident의 영향이 과하게 커질 수 있음.
SSE는 또한 크기가 큰 bbox와 작은 bbox의 오차를 동등하게 계산하기 때문에 큰 bbox의 loss를 줄여주기 위해* 높이 h와 너비 w의 loss를 계산할 때는 제곱근*을 취합니다.
*같은 거리를 움직였다고 가정하였을 때, 큰 객체를 탐지하는 bbox는 움직여도 객체를 많이 벗어나지 않지만 , 작은 객체를 탐지하는 bounding box는 객체를 상대적으로 많이 벗어나게 됨.
*제곱근을 취할 경우, 너비와 높이가 커짐에 따라 loss의 증가율은 감소
YOLO는 한 grid cell 당 B개의 bbox를 예측하는데, 하나의 객체를 탐지하는 데에는 하나의 bbox predictor만이 책임을 지도록 해야 합니다. 따라서 우리는 responsible한 하나의 bbox predictor를 할당해주어야 합니다. 이때 ground truth와의 IOU값이 할당 기준이 됩니다.

는 cell i에 객체가 있을 때만 계산이 이루어짐을 의미합니다.

는 cell i의 j번째 bbox가 responsible할 때만 계산이 이루어짐을 의미합니다.
Inference
큰 객체나 grid cell의 경계에 걸쳐 있는 객체의 경우, 여러 grid cell이 하나의 동일한 객체를 탐지하는 데 사용될 수 있습니다. 이는 NMS(Non-Maximal Suppression)를 사용하여 개선될 수 있으며, 본 논문에서도 NMS를 사용하여 23%의 mAP 개선을 이루었습니다.
Limitations of YOLO
YOLO의 한계점은 다음과 같습니다.
1. bbox에 공간적 제약이 따릅니다. 하나의 grid cell 당 하나의 class만을 가지는 두 개의 bbox만을 예측하기 때문에 여러 개의 객체가 모여있을 경우 검출에 한계를 보인다는 겁니다. 이런 문제는 특히 새의 무리 같이 작은 객체가 집단을 이루는 경우 두드러지게 나타납니다.
2. 데이터를 기반으로 bbox를 예측하기 때문에 test 단계에서 새로운 비율의 객체를 탐지하는 데 어려움을 겪습니다. 또한 input 이미지를 여러번 downsampling 하기 때문에 bbox 예측에 있어 coarse feature를 사용하게 된다는 문제도 있습니다.
3. 비록 제곱근을 취하여 작은 bbox에 비하여 큰 bbox의 error를 더 적게 고려하려고 하였으나, 큰 bbox의 오류와 작은 bbox의 오류가 동등하게 계산된다는 문제점이 여전히 남아있습니다.
Experiments
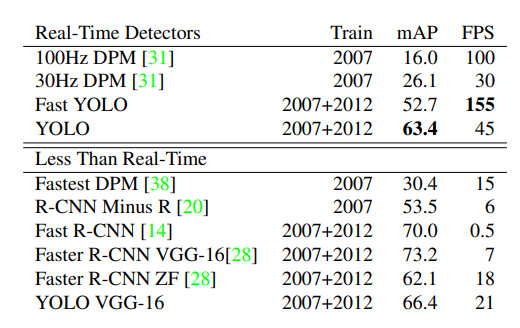
YOLO가 기존 모델에 비해 월등히 빠르다는 것을 확인할 수 있습니다.

Fast R-CNN에 비해 YOLO의 정확도가 더 낮습니다. 높은 localization error를 통해 YOLO는 위치를 정확하게 식별하는 데에 어려움을 겪는다는 것을 알 수 있습니다. 다만, Background error가 확연히 낮다는 것을 통해 contextual information을 사용하는 YOLO의 장점을 확인할 수 있습니다.





댓글 영역