고정 헤더 영역
상세 컨텐츠
본문
Abstract
- Key insight: to build
- fully convolutional networks
- that take input of arbitrary size and produce correspondingly-sized output 임의의 사이즈의 입력을 받을 수 있게끔!
- AlexNet, VGGNet, GoogLeNet과 같은 기존의 분류 모델 구조를 fully convolutional network로 변형시켜 사용. fine-tuning을 통해 segmentation task에 맞게 전이학습 진행
- 새로운 구조 제안 - deep layer에서 나온 semantic information과 shallow layer에서 나온 appearance information를 조합하여 정확하고 구체적인 segmentation 도출
Introduction
Convolution network는 객체 인식 분야에서 많은 성과를 내고 있다. Whole-image classification 뿐만 아니라 bounding box object detection, part/key-point prediction, local correspondence 등의 국소적인 task에서도 좋은 성과를 보이고 있다. 이제는 각 pixel에 대한 예측을 위한 연구가 진행되는 차례이다.
Semantic segmentation을 위해 사용되는 이전의 방식들에는 결함이 있다. Patchwise 방식은 흔하지만 효율 좋지 않고, 기존의 Pixelwise 방식 또한 결점이 존재한다. 따라서 해당 논문에서는 semantic segmentation을 위해 end-to-end, pixels-to-pixels로 학습돤 FCN을 제안한다. 이 논문은 FCN을 처음으로 pixelwise로, supervised pre-training을 통해 학습시켰으며, Skip architecture를 제시하였다.
Fully Convolutional Networks
3.1. Adapting classifiers for dense prediction

LeNet, AlexNet 등 전형적인 객체 인식 신경망은 모두 fully connected layer를 갖기에 고정된 크기의 입력을 받고, 공간 정보가 배제된 출력을 반환한다. 하지만 이러한 fc layer는 입력의 전 지역을 다루는 kernel을 갖는 convolution이라고 볼 수 있다. 따라서 fc layer를 convolution layer로 전환하면 임의의 사이즈의 입력에 대해 classification map을 출력할 수 있으며, 이 때 이 출력물은 공간 정보를 유지하게 된다. 이러한 장점으로 인해 convolutionalized model은 모든 픽셀의 레이블을 예측하는 dense prediction, 그 중에서도 semantic segmentation에 적합하다.
3.2. Shift-and-stitch is filter rarefaction
Input shifting과 output interlacing은 보간법 없이 듬성듬성한 결과를 dense prediction으로 만들 수 있는 방법이다. 하지만 해당 방법보다는 upsampling이 더 효과적이고 효율적이므로 사용하지 않는다.
3.3. Upsampling is backwards strided convolution
coarse한 결과를 dense 픽셀로 연결할 수 있는 방법이 바로 보간법, interpolation이다. 그 중 간단한 이중선형보간법은 선형 map에 따른 가장 가까운 4개의 input을 통해 output yij를 계산한다. 이 선형 map은 input과 output cell의 절대적인 위치만 고려한다.
이 때 f만큼 upsampling을 하는 것은 input stride 1/f로 convolution을 진행하는 것과 동일하기에 output stride f로 backwards convolution을 하는 방식을 대신 사용한다. 이러한 upsampling은 네트워크 내 end-to-end 학습에서 역전파로 구해진 pixelwise loss를 통해 수행된다.
Segmentation Architecture
해당 논문에서 ILSVRC classifier를 FCN으로 교체하고, upsampling과 pixelwise loss를 동반한 dense prediction을 위해 증강한다. 또한 새로운 skip architecture를 통해 넓고 의미론적인 정보와 국소적이고 외형적인 정보를 결합하고자 한다.
4.2. Combining what and where

위 그림과 같이 feature 계층의 layer들을 결합하고 output의 공간적 정확성을 높이는 FCN 구조를 새롭게 정의한다. Fully convolutionalized classifier도 segmentation task에 맞게 fine-tuning되어 좋은 성능을 낼 수는 있지만, 그 coarse한 결과를 내게 된다. 따라서 최종 예측 layer와 더 얕은 layer들을 연결하는 link를 만드는 방식으로 이 문제를 해결하고자 한다. 더 fine한 layer와 coarse한 layer를 결합하는 것은 모델이 더 local하고 전체적인 구조를 고려하는 prediction을 만드는 것에 도움을 준다.
pool4에 1x1 convolution layer를 더해 추가적인 class prediction을 만들고, 이 결과물을 기존의 conv7의 output에 합친다. 이 과정에서 conv7의 output에 2x upsampling 층이 더해진다. 이렇게 만들어진 stride 16 prediction을 다시 원 이미지의 크기만큼 upsampling하는 신경망을 FCN-16이라 한다. 마찬가지 방식으로 pool3의 prediction을 활용하여 예측을 하는 신경망을 FCN-8이라 한다.
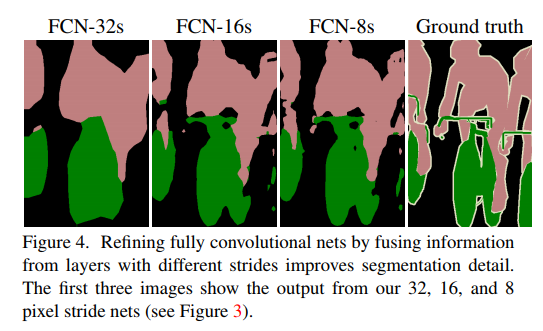
이러한 skip net은 validation set에 대한 성능의 개선으로 이어졌으며, output의 fine structure에도 영향을 주는 것을 확인할 수 있다. 특히 FCN 중에서도 더 얕은 layer의 prediction이 활용되었을 경우 더 정확한 segmentation이 가능한 것을 확인할 수 있었다.
Conclusion
Fully convolution network를 segmentation으로 확장하고, 다양한 해상도의 layer들의 결합을 통해 구조를 개선함으로써 state-of-the-art의 성능을 이룰 수 있었다. 동시에 학습과 추론 과정도 단순화하고, 그 속도도 높일 수 있었다.
'방학 세션 > CV' 카테고리의 다른 글
| [4주차 / 진유석 / 논문리뷰] Fully Convolutional Networks for Semantic Segmentation(FCN) (0) | 2023.02.08 |
|---|---|
| [4주차 / 임정준 / 논문리뷰] Mask R-CNN (2) | 2023.02.08 |
| [4주차 / 문성빈 / 논문리뷰] Fully Convolutional Networks for Semantic Segmentation (0) | 2023.02.07 |
| [4주차 / 신인섭 / 논문리뷰] Mask R-CNN (0) | 2023.02.07 |
| [4주차 / 임채명 / 논문리뷰] You Only Look Once: Unified, Real Time Object Detection (0) | 2023.02.07 |





댓글 영역