고정 헤더 영역
상세 컨텐츠
본문
Abstract
Fast R-CNN은 training/testing speed 개선과 detection accuracy 향상을 위해 improve 되었다.
Introduction
object detection은 image classification 보다 더 복잡한 방법을 사용해서 문제를 해결하기 때문에 더 어렵다. complexity로 인해서, 느리고 inelegant한 multi-stage pipeline에서 학습한다. complexity가 증가하는 이유는 detection이 물체의 정확한 localization을 필요로 하기 때문이다. 많은 수의 candidate object location이 처리되어야 하고, 이러한 candidates도 대략적인 localization만 제공하기 때문에 추가적인 처리가 필요하다. 이것을 해결하는 방법은 speed, accuracy, simplicity 요소로 구성되어 있다.
- R-CNN and SPPnet
R-CNN은 다음과 같은 단점을 가진다.
- Training is a multi-stage pipeline := R-CNN은 log loss 함수를 사용해서 object proposal에 대한 ConvNet을 finetune 시킨다. 다음으로 SVMs를 ConvNet feature에 적합시킨다. 세번째 단계로, bounding-box regressor들이 학습된다.
- Training is expensive in space and time := SVM과 bounding box regressor 학습 과정에 있어, deep network에서는 많은 저장공간과 시간이 요구된다.
- Object detection is slow := test 시에도 한 image 당 약 47초의 시간이 소요된다.
R-CNN은 computation을 공유하지 않으면서 각 object proposal에 대해 ConvNet forward pass를 진행하기 때문에 속도가 느리다. R-CNN이 computation을 공유함으로써 속도를 빠르게 하기 위해 SPPnet이 제안되었다. SPPnet은 전체 input image에 대해 convolutional feature map을 계산한 다음, 공통의 feature map에서 추출한 feature vector를 사용하여 각 object proposal을 분류한다.
이러한 SPPnet의 단점은 전체적으로 R-CNN과 학습방식이 비슷하지만, spatial pyramid pooling 이전의 convolutional layer를 update할 수 없다는 한계로 인해 deep network에서의 accuracy limit을 가진다는 점이다.
- Contributions
Fast R-CNN은 R-CNN과 SPPnet보다 더 높은 detection quality를 가지고, multi-task loss를 사용하여 single-stage에서 학습한다. 또한 학습 과정에서 모든 network layer의 update가 가능하며, feature caching을 위한 저장이 불필요하다.
1. Fast R-CNN architecture and training
Fast R-CNN의 input으로는 entire image와 set of object proposal이 해당된다. network는 첫번째로 여러 개의 conv/max pooling layers를 사용해서 전체 image를 처리하여 conv feature map을 생성한다. 다음으로, 각 object proposal에서 region of interest pooling layer가 feature map으로부터 정해진 길이만큼의 feature vector를 추출한다. 각 feature vector는 일련의 fully connected layers에 들어가 두개의 output layer로 나온다.
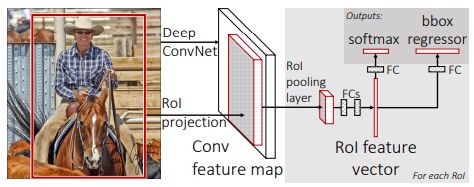
- the RoI pooling layer
RoI pooling layer는 max pooling을 사용해서 어떠한 valid region of interest 안의 feature들을 small feature map으로 변환한다. pooling은 각 feature map channel에 독립적으로 적용된다.
- Initializing from pre-trained networks
세가지 pre-trained ImageNet network를 사용해서 실험을 진행하였다. pre-trained network가 Fast R-CNN을 initialize 시킬 때 나타나는 변형은 세가지이다. 첫번째로 마지막 max pooling layer는 RoI pooling layer로 대체된다. 두번째로 network의 마지막 fully connected layer와 softmax는 앞에서 언급된 두개의 layer로 대체된다. 세번째로 network는 두개의 data input을 받도록 변형된다.
- Fine-tuning for detection
모든 network weight들을 back-propagation으로 training하는 것은 Fast R-CNN의 중요한 능력이다.
학습 중 feature sharing의 장점을 사용한 보다 효율적인 학습 방법을 제안한다. SGC minibatch는 먼저 N개의 image를 sampling한 다음 각 image에서 R/N개의 RoI를 sampling하여 계층적으로 sampling한다. 이때 N을 작게 하면 minibatch의 계산이 줄어준다. 한가지 고려해야 하는 것은 이러한 방법이 training convergence를 늦출 수 있다는 점이다. (같은 image로부터의 RoI들은 correlate 되어 있기 때문에 생기는 우려)
계층적 sampling에 더해, Fast R-CNN은 streamlined training process를 사용한다. 이것은 softmax classifier와 bounding-box regressor를 공통으로 최적화하는 하나의 fine-tuning stage를 사용한다.
[ multi-task loss]
Fast R-CNN은 두가지 output layer를 가진다. 첫번째는 K+1개의 category에 대한 이산확률분포를 가진다. 두번째는 각 K object class에 대한 bounding-box regression offset을 가진다. 각 training RoI는 실측 class u와 실측 bounding-box regression target v로 나타낸다. classification과 bounding-box regression의 train을 위해 각 labeled RoI에 multi-task loss L을 사용한다. background RoI의 경우 실측 bounding box의 개념이 없기 때문에 두번째 task에 대한 loss는 존재하지 않는다. R-CNN와 SPPnet도 classifier와 bounding-box localizer를 train시키지만, stage-wise training 방식을 사용하기 때문에 지나치다.
[ mini-batch sampling ]
최소 0.5의 실측 bounding box와 겹치는 IoU(Intersection over Union)가 있는 object proposal에서 RoI의 25%를 가져온다. 나머지 RoI는 [1.0, 0.5) 간격의 실측값을 가진 최대 IoU가 있는 object proposal에서 sampling 된다.
[ back-propagation through RoI pooling layers ]
RoI pooling layer의 backward 함수는 argmax switch를 따라 각 입력 변수 Xi에 대한 손실 함수의 partial derivative를 계산한다.
[ SGD hyper-parameters ]
softmax classification과 bounding-box regression에 사용된 fully connected layers는 zero-mean Gaussian distribution으로부터 initialized 되었다. 더 큰 dataset에서 train 할수록, SGD를 더 많은 iteration에 대해 작동시킨다.
- Scale invariance
scale invariant를 위해 두가지 방식을 사용해 보았다. 첫번째는 brute force 학습 방식을 통해서 인데, 이때에는 각 image가 train과 test 중에 미리 정해진 pixel 크기로 처리된다. network는 training data로부터 scale-invariant object detection을 직접적으로 배우게 된다. 두번째는 image pyramids를 사용하는 방법이다. image pyramid를 사용해서 근사적 scale-invariance르 제공하는 것이다. test 시에는, image pyramid가 각 object proposal의 scale-normalize를 근사하는데 사용된다.
2. Fast R-CNN detection
각 test RoI에 대해, forward pass는 class의 사후확률분포 p와 r에 대한 예측된 bounding-box offset 집합을 출력한다.
- Truncated SVD for faster detection
전체 image classification에 있어서, fully connected layer가 conv layer를 계산하는 것보다 더 적은 시간이 걸렸다. 반면 detection에 있어서는, fully connected layer를 계산하는데 걸린 시간이 거의 반 정도 밖에 안 걸렸으며 처리되어야 하는 RoI의 개수가 더 많았다. large fully connected layer는 truncated SVD로 압축함으로써 더 쉽게 가속화되었다.
network를 압축시키기 위해, single fully connected layer는 두개의 fully connected layer로 대체되었다. 이러한 간단한 압축 방식은 RoI의 수가 많을 때 속도를 높이는데 도움을 준다.
3. Design Evaluation
- Does multi-task training help?
multi-task training은 동일하게 train된 task의 pipeline을 고려하지 않기 때문에 편리하다. 하지만 이것은 또한 task들이 서로 shared representation을 통해 영향을 주기 때문에 결과 개선의 가능성을 가진다. 세가지 모델을 가지고 실험해 본 결과, multi-task training은 classification만을 위한 training에 비해 순수한 classification의 정확도를 향상시킴을 확인하였다. 하지만 stage-wise training은 multi-task training 보다 결과가 좋지 않다.
- Scale invariance: to brute force or finesse?
deep ConvNet은 scale invariance를 직접적으로 학습하는 것에 능숙하다.
- Do we need more training data?
좋은 object detector는 더 많은 training data를 사용했을 때 향상되어야 한다. 실험 결과, VOC10과 12 모두 향상됨을 확인하였다.
- Do SVMs outperform softmax?
Fast R-CNN은 fine-tuning 동안 softmax classifier를 사용하는데, 세 모델 모두 softmax가 SVM 보다 높은 성능을 보인다. 이것의 영향은 작지만, 이전의 multi-stage training 접근 방식에 비해 ‘one-shot’ fine-tuning이 충분함을 나타낸다.
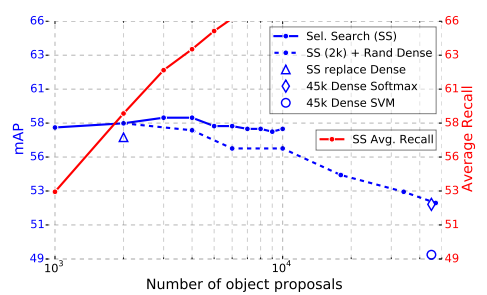
- Are more proposals always better?
object detector는 sparse/dense한 object proposal을 사용한다. sparse proposal을 분류하는 cascade가 Fast R-CNN의 accuracy를 향상시킨다는 증거를 발견했다. 또한 실험을 통해 더 많은 proposal으로 deep classifier를 채우는 것이 꼭 도움이 되는 것은 아님을 보여주고, 심지어 약간 떨어지는 accuracy 가짐을 보여준다.
Conclusion
이 글은 Fast R-CNN이 R-CNN과 SPPnet이 깔끔하고 빠르게 향상된 모델이라고 제안한다. 또한 sparse object proposal이 detector의 질을 향상시킬 수 있는 가능성을 보인 것에 의의를 가진다.
'방학 세션 > CV' 카테고리의 다른 글
| [2주차 / 신인섭 / 논문리뷰] Deep Residual Learning for Image Recognition (1) | 2023.02.01 |
|---|---|
| [3주차 / 천원준 / 논문리뷰] Rich feature hierarchies for accurate object detection and semantic segmentation (1) | 2023.02.01 |
| [3주차 / 임채명 / 논문리뷰] Fast R-CNN (0) | 2023.02.01 |
| [3주차 / 황민아 / 논문리뷰] Fast R-CNN (0) | 2023.02.01 |
| [2주차 / 천원준 / 논문리뷰] Going deeper with convolution (0) | 2023.02.01 |





댓글 영역