고정 헤더 영역
상세 컨텐츠
본문
1. Introduction
Object detection을 위한 기존의 R-CNN 방식은 몇 가지 단점이 존재하였다.
- 학습 과정이 multi-stage pipeline으로 구성되어 있다.
- 학습이 공간, 시간적으로 비싸다.
- Object detection 속도가 느리다.
R-CNN의 속도 문제를 보완하기 위해 SPPnet라는 새로운 방식이 제안되었으나 학습이 multi-stage pipeline으로 구성되며 SPP층 전의 convolution층은 업데이트를 할 수 없다는 단점이 존재하였다.
해당 논문에서는 R-CNN과 SPPnet의 단점과 속도, 정확도를 개선하기 위해 Fast R-CNN이라는 새로운 방법을 제안한다.
2. Fast R-CNN Architecture and training
Fast R-CNN의 구조는 다음과 같다.

Input으로는 완전한 이미지와 object proposal set을 받는다. 이미지가 convolution, max pooling 층을 지나며 feature map이 생성되며, 각 object proposal에 대해 RoI pooling layer는 고정된 길이의 feature vector를 추출해낸다. 추출된 feature vector는 fc층에 입력되어 softmax, bbox regression 과정을 거친다.
RoI pooling layer

ROI pooling layer는 SPPnet의 SPP layer의 한 형태로, pyramid level이 1이다.
RoI pooling layer는 region of interest의 feature map을 H x W의 고정된 크기로 변환하기 위해 max pooling을 사용한다. 이 때 H와 W는 layer hyperparameter이다. 변환을 위해 h x w의 RoI window를 각각 h/H x w/W의 sub-window로 나눈 후 각 구역의 최대값을 max-pooling해 온다.
Initializing from pre-trained networks
해당 논문에서는 3 종류의 pre-trained ImageNet network를 사용하였으며, 각각은 5개의 max pooling 층과 13개의 conv 층으로 구성된다.
Pre-trained 네트워크를 사용하기 위해 3 과정을 거친다.
- 마지막 max pooling layer는 RoI pooling layer로 대체한다. H,W는 첫 fc layer에 맞추어 설정한다.
- 마지막 fc layer와 softmax는 K+1개의 카테고리에 대한 softmax와 bounding-box regressor로 대체한다.
- 네트워크가 두 개의 입력 - 이미지들과 각 이미지에 대한 RoI 를 받을 수 있게 수정한다.
Fine-tuning for detection
Fast-RCNN은 효율적인 학습을 위해 hierarchical sampling을 사용한다. 또한 multi-task loss를 통해 softmax classifier와 bounding-box regressor를 한 번의 fine-tuning으로 학습시킨다.
Multi-task loss
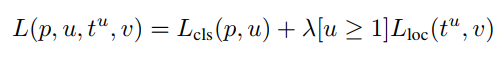
Fast R-CNN은 두 개의 출력층 - K+1개의 카테고리에 대한 확률분포를 출력하는 softmax 층과 bounding-box regression 층으로 구성된다. Training에 사용되는 각 RoI는 ground-truth 클래스 u와 ground-truth bbox target v로 레이블되며, multi-task loss L을 통해 classification과 bounding-box regression의 학습이 동시에 진행된다.
Loss의 첫번째 부분은 classification에 대한 loss로 다음과 같다.

Loss의 두번째 부분은 localization에 대한 것으로 다음과 같다.


배경에 대한 RoI의 경우 해당 loss는 무시된다. Smooth L1 loss는 R-CNN과 SPPnet에서 사용되는 L2 loss에 비해 outlier에 대해 덜 민감하며, exploding gradient 문제를 방지할 수 있다.
3. Conclusion
해당 논문은 fast R-CNN을 제안함으로써 기존의 R-CNN, SPPnet보다 더 빠른 학습과 테스트가 가능하게 했다. 속도 뿐만 아니라 mAP 또한 VOC07, 2010, 2012에 대해 State-of-the-art를 기록할만큼 향상되었다.
'방학 세션 > CV' 카테고리의 다른 글
| [3주차 / 윤지현 / 논문리뷰] Fast R-CNN (1) | 2023.02.01 |
|---|---|
| [3주차 / 임채명 / 논문리뷰] Fast R-CNN (0) | 2023.02.01 |
| [2주차 / 천원준 / 논문리뷰] Going deeper with convolution (0) | 2023.02.01 |
| [2주차 / 황민아 / 논문리뷰] Deep Residual Learning for Image Recognition (0) | 2023.01.31 |
| [2주차 / 윤지현 / 논문리뷰] Deep Residual Learning for Image Recognition (0) | 2023.01.31 |





댓글 영역