고정 헤더 영역
상세 컨텐츠
본문
Abstract
본 논문에서는 R-CNN이나 SPPnet보다 연산속도나 정확도 면에서 성능이 뛰어난 Fast R-CNN을 소개합니다.
Introduction
object detection은 물체들의 정확한 위치를 구하기 위해 위치 후보를 선정하고 이 후보들을 통해 정확한 위치를 도출하는 과정을 거칩니다. 기존의 object detection 모델들은 이 과정들은 나누어 연산하는 multi-stage pipeline으로 구성되어있었던 반면, 본 논문에서는 single stage 학습을 하는 Fast R-CNN을 제안합니다.
1. R-CNN and SPPnet
R-CNN은 다음과 같은 문제점이 있습니다.
1. 학습 과정이 multi stage로 구성되어 있다.
Selective Search로 위치 후보를 선정하고 (1) 위치 후보에 대해 ConvNet을 finetune한 후, (2) 학습한 feature를 사용하여 SVM Classifier를 fit하고 마지막으로, (3) bounding bow regressor 학습하는 과정을 거쳐야 한다.
2. 연산이 느리고 메모리를 많이 차지한다.

R-CNN이 위치 후보 각각에 대해 ConvNet을 학습시켜 느리기 때문에 SPPnet은 전체 input 이미지에 대한 featuremap을 만든 후, 이 featuremap에서 각 위치 후보에 대한 feature 벡터를 max pooling으로 추출하여 사용(spatial pyramid pooling)합니다. SPPnet을 통해 R-CNN에 비해 연산속도가 빨라졌으나, 여전히 학습 과정이 multi stage로 구성되어 있다는 문제점이 있으며, R-CNN과는 달리 spatial pyramid pooling 과정 이전에 위치하는 Conv layer에 대한 가중치를 업데이트하는 것이 불가능하다는 문제 또한 존재합니다.
2. Contributions
Fast R-CNN은 이러한 한계점을 극복하여 다음과 같은 장점을 지닙니다.
1. 더 높은 mAP
2. multitask loss를 사용하여 single stage 학습이 가능
3. 학습 과정에서 모든 layer의 가중치 업데이트 가능
4. feature 저장을 위해 디스크를 사용하지 않음
Fast R-CNN architecture and training

Fast R-CNN의 구조는 다음과 같습니다.
1. 전체 이미지를 몇 개의 Convolution layer와 max pooling layer로 구성된 모델에 넣어 Conv feature map을 얻습니다.
2. Selective Search를 사용하여 위치 후보(Region of Interest) 선정 (RoI projection)*
3. 각각의 위치후보에 대해 RoI pooling layer가 feature map에서 고정된 크기의 벡터를 추출합니다.
4. 각 feature 벡터는 두 개의 fc layer를 거쳐 결국 (1) classification(K + 1)*을 위한 softmax layer와 (2) bounding box의 위치를 조정하기 위한 4개의 실수를 output으로 출력하는 layer의 input으로 사용됩니다.
*결국 Selective Search는 Fast R-CNN과 별개의 과정이기 때문에 Fast R-CNN의 input은 전체이미지와 위치후보(RoI list) 두 가지입니다.
*object 개수 K개에 background class 1개를 더한 K + 1개의 class에 대한 classification
1. The RoI pooling layer
Fast R-CNN의 첫번째 특징은 RoI pooling layer를 도입했다는 점인데, RoI pooling layer는 앞서 등장한 spatial pyramid pooling layer에서 추출에 사용되는 영역, 즉 pyramid가 하나인 경우입니다. 이때 사용되는 영역(RoI window)의 크기는 (r, c, h, w)로 나타낼 수 있으며 (r, c)는 좌측 상단의 모서리를 의미하며 (h, w)는 높이와 너비를 의미합니다. RoI window를 HxW grid*의 sub-window로 나누어 각 sub-window에서 max-pooling을 진행하여 값을 추출하는 것이 RoI pooling입니다.
* HxW는 sub-window의 크기가 아니라 ouput의 크기이며, 조정 가능한 하이퍼 파라미터입니다.
2. Initializing from pre-trained networks
본 논문에서는 pre-trained된 ImageNet 모델 3개를 변형하여 사용합니다.
1. 마지막 max pooling layer를 RoI pooling layer로 바꾸어줍니다. 이때 H, W의 크기는 fc layer와 호완 가능하도록 설정해줍니다.
2. 모델의 마지막에 위치한 fc layer와 softmax layer를 위에서 설명한 두 가지 layer로 바꾸어줍니다.
classification을 위한 softmax layer와 bounding box의 위치 조정을 위한 layer
3. 전체 이미지와 RoI list를 input으로 받을 수 있도록 바꾸어줍니다.
3. Fine-tuning for detection
효율적인 역전파 계산을 위해 본 논문에서는 다음 방법을 도입합니다.
1. hierarchical mini-batch sampling: N개의 이미지를 먼저 sampling하고 이후 각 이미지에 대해 R/N개의 RoI를 sample. N이 작을수록 계산이 효과적이다. 본 논문에서는 N = 2의 이미지에서 R = 128, 즉 각 이미지에 대해 64개의 RoI를 sampling하였다. 이때 hard example mining을 위해 ground-truth bounding box와의 IoU 값이 0.5 이상인 RoI 중에서 16개(25%)를 sampling하고 나머지 75%는 IoU값이 0.5 미만인 RoI에서 뽑는다. IoU값이 0.5 미만인 RoI는 background example이 되어 0으로 라벨된다.
2. Multi-task loss: 이로 인하여 single stage 학습이 가능

p: classification score (p_0, ..., p_k)
t: bounding box regression score (t_kx, t_ky, t_kh, t_kw)
u: ground-truth class (background class의 경우 u = 0)
v: ground-truth bounding box regression target
λ: 하이퍼 파라미터로 본 논문에서는 항상 λ=1 사용
- classification loss: L_cls(p, u) = − log(p_u)로 cross entropy loss를 사용한다.
- bounding box regression loss: L_loc(t_u , v)로 이상치에 덜 예민한 smooth L1 loss를 사용하여 다음과 같이 계산한다.
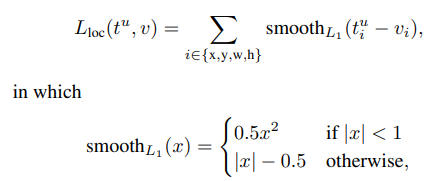
4. Back-propagation through RoI pooling layers
SPPnet은 SPP 이전의 Conv layer에 대한 가중치를 업데이트하는 것이 불가능하다는 한계가 있었기 때문에 본 논문에서는 이를 RoIPooling layer 이전까지 Back Propagation을 진행할 수 있음을 보이고 있습니다.
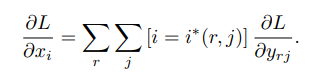
x_i가 r번째 ROI에서 J번째(index가 j인) sub-window에서 max pooling에 의해 선택된 값인 경우, 편미분 값인 dL/dy_rj가 계속 더해집니다.
Conclution
본 논문에서는 SPPnet과 R-CNN의 문제점을 지적하며 이를 극복하는 방법으로 Fast R-CNN을 제안하고 있습니다. Fast R-CNN은 RoI pooling layer와 classification 과정에서 softmax layer의 사용, single stage training을 위한 Multi-task loss 등을 통해 성능 향상을 이끌어냈습니다. 그러나 아직 Selective Searching을 통해 RoI를 선정한다는 점에서 진정한 end-to-end model이라고 보기엔 한계가 있습니다.
'방학 세션 > CV' 카테고리의 다른 글
| [3주차 / 천원준 / 논문리뷰] Rich feature hierarchies for accurate object detection and semantic segmentation (1) | 2023.02.01 |
|---|---|
| [3주차 / 윤지현 / 논문리뷰] Fast R-CNN (1) | 2023.02.01 |
| [3주차 / 황민아 / 논문리뷰] Fast R-CNN (0) | 2023.02.01 |
| [2주차 / 천원준 / 논문리뷰] Going deeper with convolution (0) | 2023.02.01 |
| [2주차 / 황민아 / 논문리뷰] Deep Residual Learning for Image Recognition (0) | 2023.01.31 |





댓글 영역