고정 헤더 영역
상세 컨텐츠
본문

본 게시글은 강필성 교수님의 다변량 데이터 분석 강의를 기반으로 작성되었습니다.
작성자 : KUBIG 17기 송지훈
Chapter 4) Dimensionality Reduction
4-1 Dimensionality Reduction
이론상, 변수들이 독립적인 가정하에, 변수가 증가할수록 모델 성능도 향상
- 현실에서는 변수가 독립적인 경우가 거의 없고, noise 존재 때문에 변수가 증가할수록 모델 성능이 좋아지지 않는다
목적: 모델의 효율성 추구 -> 원래 n개의 변수를 사용한 모형이 차원 축소한 n' 개의 변수를 사용한 모형과 비슷하다
- 예측 모델에 가장 잘 맞는 subset of variable 찾기
차원 축소의 효과:
- 변수 사이의 상관성 제거 -> 변수 독립
- 사후 processing 단순화
- 중복되거나 불필요한 변수 제거
- 시각화 수월
[Curse of Dimensionality]
변수 개수가 증가하면 정보량을 보존하는데 필요한 관측치는 기하급수적으로 증가한다
차원 축소를 할 수 있는 이유: 내재적 차원이 실제 가지고 있던 차원보다 낮을 확률이 높다
높은 차원으로 발생하는 문제들:
- 데이터에 Noise가 있을 확률이 증가한다 -> 예측 성능이 떨어진다
- 계산 시간이 증가한다
- 성능 좋은 모델링을 하기 위해서 더 많은 수의 example이 필요하다
차원의 저주를 해결하기 위한 방안:
- Domain Knowledge 사용 (전문성)
- 적은 수의 변수를 선호하는 regularization term을 추가
- 정량적인 변수 축소 technique 사용
[Dimensionality Reduction]
Supervised vs Unsupervised Dimensionality Reduction
[Supervised]
모델/알고리즘 개입하여 피드백으로 제일 좋은 조합 찾기
[Unsupervised]
모델/알고리즘 개입하여 피드백이 없다
한 번에 차원 축소를 진행한다
[Dimensionality Reduction Technique]
- Variable/Feature Selection
- 존재하는 변수 중에서 부분 집합으로 변수 몇 개를 뽑는 것
- Variable/Feature Extraction
- 존재하는 변수를 사용해서 새로운 변수를 만들어내는 것
4-2 Variable Selection Methods
[Exhaustive Search]
모든 가능한 조합 테스트
ex) x1부터 x3이 있으면 총 7가지를 시도
단점: 시간 소요가 어마하다
[Forward Selection]
변수 아무것도 사용하지 않는 모델부터 시작해서 중요할 것을 생각되는 변수들이 순차적으로 추가된다
- 변수가 한번 추가되면 제거되지 않는다
- 추가 변수를 탐색했을 때 성능 향상이 유의미하지 않을 때 종료
[Backward Elimination]
모든 변수를 가진 모델부터 시작해서 중요하지 않은 변수들이 순차적을 제거된다
- 한번 제거되면 추가되지 않는다
- 어떤 변수를 빼도 성능의 저하가 급격하게 일어난다면 변수 제거하지 말자
Backward Elimination, Forward Selection 둘 다 속도는 빠르지만, 성능 하락이 꽤 있다
[Stepwise Selection]
변수가 없는 모델부터 시작해서 forward selection, backward elimination 번갈아 가면서 수행
- Forward selection과 backward elimination보다 시간은 더 걸리지만 성능 올라갈 가능성은 커지다
- 제가/추가된 변수는 다시 추가/제거될 수 있다
Forward, Backward, Stepwise Selection 모두 효율적이지만 search space가 한정되어 있으니 가장 optimal 한 설정을 찾을 확률이 낮다
[Performance Metrics]
- Akaike Information Criteria (AIC)
$$ \text { Sum of squared error (SSE) } = \sum_{i=1}^n (y_i - \hat{y_i})^2 $$
$$ AIC = n * ln({SSE \over n}) + 2k $$
k = 변수 개수,
n = 관측치 개수
첫 파트는 같은 변수의 개수라면 성능을 향상, 두 번째 term은 같은 성능이라면 변수의 개수를 줄임 -> AIC는 낮을수록 좋다
- Bayesian Information Criteria (BIC)
$$ BIC = n * ln({SSE \over n}) + {2(k+2)n\sigma^2 \over SSE} - {2n^2\sigma^4 \over SSE^2} $$
AIC와 똑같은 목적, 하지만 표준편차 추가
- Adjusted $R^2$
[Genetic Algorithm]
Meta-Heuristic Approach: 복잡한 문제를 효율적인 시행착오를 통해 풀어나가는 것
Genetic Algorithm: 진화를 모사한 알고리즘
- Selection: 현재의 객체 중에서 상대적으로 우수한 것 찾기
- Crossover: 기준 객체를 가지고 새로운 대안 찾기
- Mutation: local optima를 탈출할 수 있는 돌연변이 제공
- Initialize chromosomes
- Binary encoding이 가장 많이 쓰인다
- 변수와 binary encoding 된 것을 chromosome
- 변수 하나와 해당하는 binary encoding이 gene
- 1이면 변수 사용, 0이면 변수 사용 X
- Model training based on chromosomes
- Chromosome 개수 - Population
- Population을 몇으로 설정 (보통 50-100)
- Fitness function 정의
- Crossover Mechanism 설정
- Rate of Mutation 설정
- Stopping Criteria 지정
- Fitness evaluation
- 어떤 chromosome이 나은지 알려주는 지표
- Fitness 값이 클수록 chromosome이 좋다
- Fitness 값이 같은 chromosome이 있으면, 변수가 더 적은 것 선택
- 같은 개수의 변수가 있으면, 예측 성능이 더 좋은 chromosome 선택
- Linear Regression 같은 경우에는 Adjusted $R^2$, AIC, BIC가 fitness function
- Selection good chromosomes
- 시작 population에서 우수한 일부만 추출
[Deterministic Selection]
상위 n % 의 chromosome 선택, 하위 (100-n)% 는 선택 X
[Probabilistic Selection]
- 각 chromosome의 fitness 값에 따라 가산점 부여
- 우수한 chromosome이 뽑힐 확률이 높지만 낮은 chromosome도 뽑힐 기회를 준다
- Create next generation: Crossover & Mutation
[Crossover]
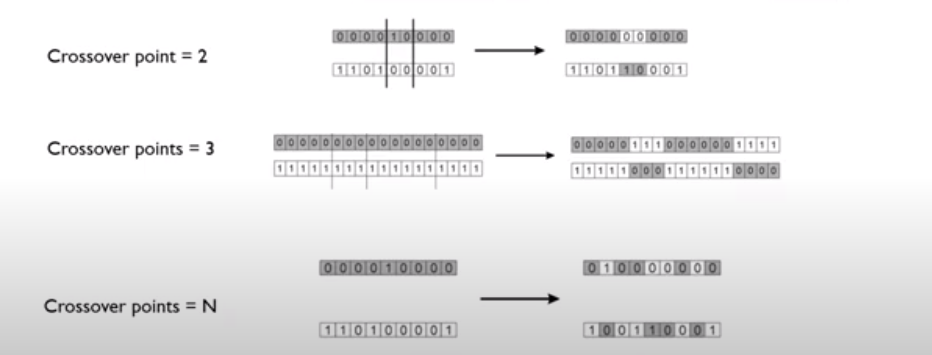
- 두 개의 부모 chromosome에서 두 개의 child chromosome이 생성된다
- crossover point는 1부터 total number of genes 개까지 가능
[Mutation]
- local optima에 걸려 있으면 mutation을 통해서 global optima를 찾을 기회 제공
- mutation rate 보통 0.01 이하
- Select the final variable set
- 2-5단계를 계속 반복하면서 Stopping Criteria를 충족시키는 Fitness 값이 큰 chromosome을 선택
- 초반에 fitness 값이 많이 좋아지고 갈수록 미미해진다
4-3 Shrinkage Methods
[Ridge Regression]
Linear, Logistic에 둘 다 사용 가능
각 objective function에 $$ + \lambda \sum_{j=1}^d \hat{\beta}_j^2 $$
- L2 norm penalty
- 두 모델이 성능이 같다면 regression coefficient가 작은 것을 선호
- 제곱이기에 0이 될 수 없음 -> variable selection으로 사용 못함
- 변수 사이에 높은 상관관계가 있다면 효과적
[LASSO]
Least Absolute Shrinkage and Selection Operator
$$ + \lambda \sum_{j=1}^d |\hat{\beta}_j| $$
- L1 norm penalty
- 덜 중요한 회귀 계수를 0으로 만들 수 있다 -> Variable selection 때 사용 가능
- Selected 된 변수 개수는 $\lambda$ 값에 따라 달라진다
- 람다가 클수록 더 많은 베타 값들을 0에 가깝게 만든다
- 람다가 작으면 베타 값을 절댓값으로 0이 아닌 값을 가짐
[Elastic Net]
Ridge의 장점 (변수 사이의 상관관계를 제외할 수 있다), LASSO의 장점 (Variable Selection) 결합
$$ + \lambda_1 \sum_{j=1}^d |\hat{\beta}j| + \lambda_2 \sum_{j=1}^d |\hat{\beta}j| $$
$\lambda_1$이 커지면 변수의 개수 감소
$\lambda_2$이 커지면 변수의 선택에 대한 impact 감소
- Backward Selection이 예측 정확도에, 변수 감소율, 계산 효율성에서 항상 위에 봤던 변수 선택 방법 중에서 Top 3안에 들었다
'심화 스터디 > 다변량 분석 스터디' 카테고리의 다른 글
| [다변량 데이터 분석] Chapter.06 Artificial Neural Networks (1) | 2023.05.04 |
|---|---|
| [다변량 데이터 분석] Chapter.05 (0) | 2023.03.28 |
| [다변량 데이터 분석] Chapter.03 (0) | 2023.03.19 |
| [다변량 데이터 분석] Chapter.02 (0) | 2023.03.13 |
| [다변량 데이터 분석] Chapter.01 (0) | 2023.03.13 |





댓글 영역