고정 헤더 영역
상세 컨텐츠
본문
1주차에서 배웠던 내용들에서 모든 데이터는 독립적인 시행들이었다.
그러나 데이터들이 서로 독립이 아닐 때가 존재한다. 예를 들어 주가데이터 같은 경우, 전날 데이터가 그 다음 날 데이터에 영향을 끼치기 마련이다.
우리는 Latent State Variable(잠재변수) Z1, Z2, Z3, ..., ZT로 데이터 간 관계를 찾고자 한다. (각 아래첨자는 특정 시간 1≤t≤T 에 대한 인덱스를 의미한다.) 잠재변수는 우리에게 보여지지는 않지만 X1, X2, X3... 의 관계를 파악하기 위해 필요한 값이다. 각각의 데이터 X1, X2, X3,...XT은 우리에게 보여지는 관찰값이며, 잠재변수들을 통해 유추할 수 있는 값이다. 1,2,3는 특정한 시간 1또한 π는 Initial State Probability를 의미하며, 해당 값을 통하여 Latent State Variable을 확인할 수 있다. 아래 그림을 보면 이해가 편할 것이다.
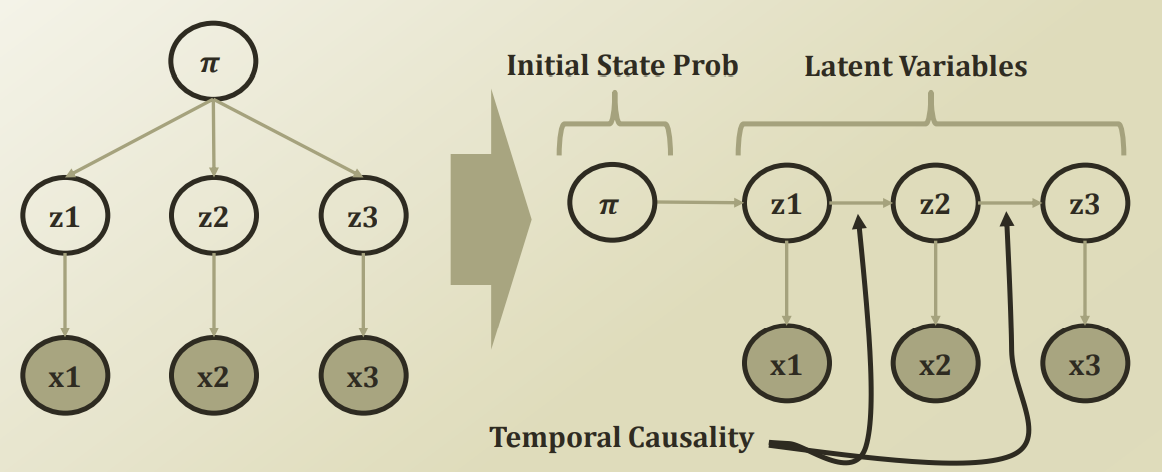
참고로 관측값, 잠재변수 모두 이산형, 연속형으로 표현할 수 있다. 그러나 본 강의에서는 이산형인 경우만 고려하며, 잠재변수가 연속형인 경우 Kalman filter이라는 방식을 활용한다고 한다. (해당 강의에서는 다루지 않을 것이라고 한다.)
Hidden Markov Model의 확률
Initial State Probabilities: 첫번째 잠재변수 Z1이 가질 수 있는 cluster들에 대한 확률이다. k개의 cluster들이 있으면 이는 이산형이기 때문에 multinomial distribution의 형태를 따를 것이다. (그림상 왼쪽에서 첫번째 가로 화살표)
Transition Probabilities: Zit-1=1, 즉 t-1 시점에서 i번째 cluster에 할당되었을 때, Zjt=1, 즉 t시점에서 j번째 cluster에 할당될 확률을 나타낸다. 우리는 이를 ai, j의 형태로 나타낸다. t-1시점에 잠재변수가 있을 때 t시점의 잠재변수가 있을 확률과 동일하다. (그림상 왼쪽 첫번째 가로 화살표를 제외한 가로 화살표)
Emission Probabilities: Zit=1, 즉 t 시점에서 i번째 cluster에 할당되었을 때, Xjt=1, 즉 t시점에서 j번째 cluster에 할당될 확률을 나타낸다. 우리는 이를 bi, j의 형태로 나타낸다. 특정 잠재변수가 있을 떄 특정 observation이 나올 확률과 동일하다. (그림상 세로 가로 화살표)

또한 t번째 시점에서 특정 잠재변수가 k번째 cluster에 속할 때, X1, X2,...,Xt 가 나올 확률은 다음과 같이 표현할 수 있다.
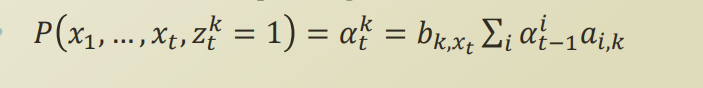
Hidden Markov Model의 질문들
M = Hidden Markov Model의 structure이라고 했을 때, Hidden Markov Model은 아래와 같은 질문들을 던진다.
Evaluation Question: P(X|M, π, a, b) - 훈련된 모델에 확률들이 주어졌을 때, 특정 observation이 나올 확률?
Decoding Question: argmaxzP(Z|X, M, π, a, b) - 특정 observation과 확률들이 주어졌을 때, 그 때 특정 잠재변수가 나올 확률?
Learning Question: argmaxπ, a, bP(X|M, π, a, b) - Observation의 확률값들을 최대화시키는 각각의 확률값들이 무엇일까?
Forward Probability
Forward Probability는 Learning Question을 해결한다. Forward Probability의 계산법은 아래 알고리즘을 보면 이해할 수 있다.

그러나 Foward probability를 구하는 알고리즘에서 t번째 시점의 observation을 확인하기 위해서는 t시점 이후의 observation들은 사용되지 않는다는 단점이 있다. 이를 개선하기 위한 Backward Probability가 존재한다. Backward probability는 t시점에 잠재변수의 cluster이 주어졌을 때, 그 이후 시점에서의 observation들이 나올 확률을 의미한다. 그리고 특정 시점 t에 잠재변수의 cluster에 할당될 확률은 forward probability랑 backward probability의 곱으로 확인할 수 있다.

*본 게시글의 글 및 그림은 모두 KAIST AAILAB 유투브채널에서 가져온 자료들이다.
'심화 스터디 > 수리적 심화 머신러닝 & 생성모델 스터디' 카테고리의 다른 글
| Week 3 Gaussian Process (37~40) (0) | 2023.05.18 |
|---|---|
| [5/6주차] Variational Inference in LDA (1) | 2023.05.13 |
| [2주차 Forward, Rejection, Importance Sampling & Markov Chain, MCMC] - 목진휘 (0) | 2023.03.22 |
| [1주차 MLE, MAP & Entropy] - 목진휘 (0) | 2023.03.22 |
| [1주차 K-mean clustering & Gaussian Mixture Model 신인섭] (0) | 2023.03.12 |





댓글 영역