고정 헤더 영역
상세 컨텐츠
본문
본 게시물은 KAIST 문일철 교수님의 기계학습 유튜브 강좌를 참고하여 만들었습니다.
Week1. Variational Inference : 12~ 18
Variational Inference
Week12. Dirichlet Distribution and Exponential Family
목적: LDA에 대해 VI 유도를 위해 Dirichlet Distribution(이하 D.D)의 특성과 pdf를 아는 것이 중요
- LDA: Latent Dirichlet Allocation, 토픽 분류 모델
Dirichlet distribution
✔️DD가 어디서 쓰이냐!!


𝜽의 pdf는 DD에서 샘플링된 것으로 나온 𝛼에 기반

- 𝜽와 𝛼 는 k-size vector
✔️그럼 특정 𝜽값이 나올 확률이 높을까 낮을까?를 알아보기!
즉, 디리쉬렛 분포 모양 알아보기
다음과 같은 조건이 만족이 되는 상황에서 DD가 정의됨.

- k-1 까지 0보다 크고 1보다 작다
- k번째까지 다 합했을 때, 1
→ x: probability simplex 잘 만족 ⇔ 이 분포에서 나온 x들은 확률로서 이용될 수 있다.
→ 이 x를 바로 multinomial distn의 parameter로 이용 ← DD에서 그 파라미터를 생성!
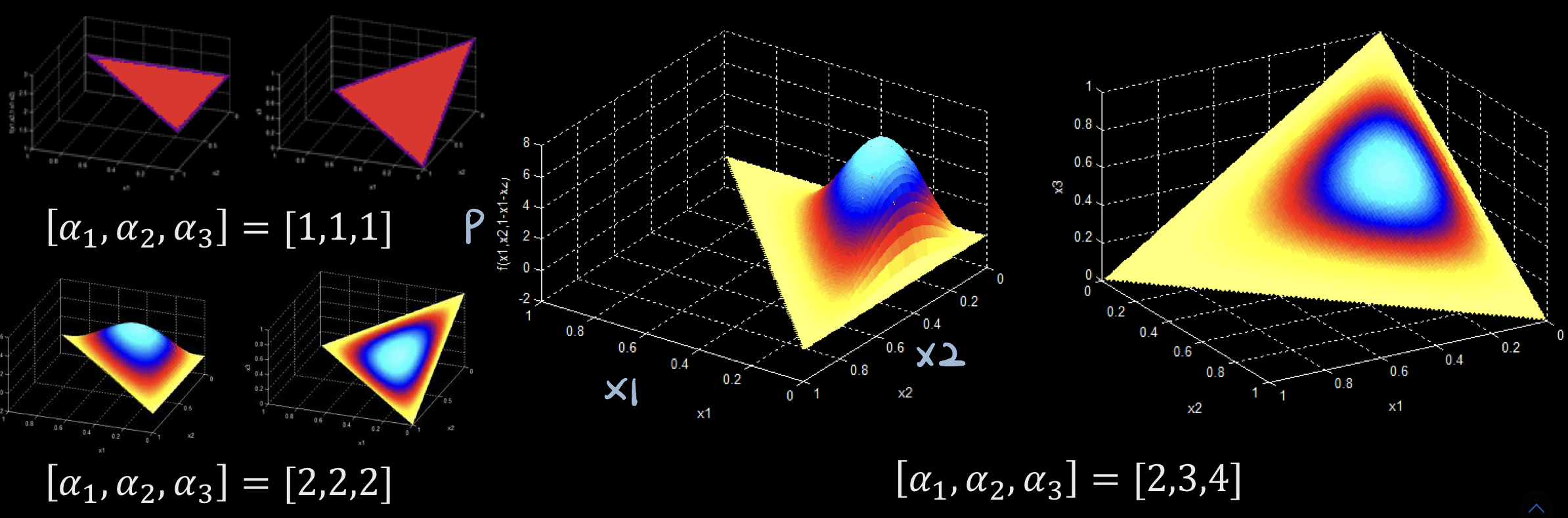
그래서 나머지 두개가 결정되면 x3은 자동적으로 결정되니, 두가지 축(x1, x2)뿐이 없음!
- [1, 1, 1] 일 경우, uniform
- [2, 2, 2]와 비교했을 때 [2, 3, 4] 일 경우, 한쪽으로 치우쳐 E있음.
Exponential Family
목적: VI에서 쉬운 계산을 위해 알아야함! → 이 EF 특징 활용하면, 쉽게 계산 가능.
Exponential Family
x의 pdf가 다음과 같이 표현되면 지수족에 속한다.

- T(x): Sufficient statistic
- 충분통계량: 모수𝜽를 추정하는데에 필요한 정보를 다 가지고 있는 통계!
- T함수로 프로세싱된 x의 정보를 이용한다.
- 𝜼(𝜽): Natural parameter
- 의미론적 관점이 아닌 수리적 관점에서 수식에 적용될 수 있도록 변형 파라미터
- 의미론적 관점 파라미터: 정규분포에서 mu는 꼭대기 부분의 x값
- h(x): Underlying measure
- A(𝜽): Log normalizer
Normal과 Dirichlet distribution이 EF임을 증명

Theorem. Derivative of log normalizer → Moments of sufficient statistics

- 𝜼는 𝜽로 표현할 수 있어서, log normalizer을 𝜽 대신 𝜼로 미분 진행
- log normalizer은 summation 진행 시 1이 되어야함을 활용한다.
- 결론적으로, T(x)가 새로 생겨 T함수의 기댓값이 된다.
→ log normalizer 미분하면, 충분통계량의 기댓값(적률)이 된다.
Week13~18. LDA의 Variational Inference
Varational distribution의 목적: 복잡한 함수를 단순화된 형태로 표현하기 위함
- Variational parameter 도입
LDA에서의 Variation distribution 전개 흐름

기존 LDA에서 𝜽와 z의 분포를 바로 찾기가 어려워서, 복잡한 모델을 approximation 하는 Variational Distribution(이하 V.D) 가정을 넣는다.
- 𝜽 ← 𝛾
- z ← 𝜙
𝛾와 𝜙라는 variational parameter를 도입하여 V.D를 가정한다.

<Variational inference 과정>
- V.D 활용하여 ELBO를 표현하기
- ELBO식을 일반적인 수식의 형태로 바꾸기
- 2번 식을 미분하여 parameter(𝛾, 𝜙, 𝛼, 𝛽) optimization하기
1. V.D 활용하여 ELBO를 표현하기
Evidence Lower Bound 목적: parameter optimization을 위함
- ELBO가 max할 때 확률이 높아지므로, 그때의 parameter값을 구하기

Variational parameter를 도입하여 ELBO를 표현하면 다음과 같다

- 𝛾, 𝜙 : Variational parameter
- 𝛼, 𝛽 : Model parameter
이는 위의 사진의 식처럼 3개의 Expectation(➀➁➂) 과 하나의 Entropy(➃)로 쪼개진다.
이를 그대로 활용하기엔 계산이 어려워 일반적인 수식의 형태로 나타낸다.
2. ELBO식을 일반적인 수식의 형태로 바꾸기
- mathematical Dierivative를 통해 plane term으로 나타낸다
- 이부분은 직접 강의를 통해 이해하면 좋을 듯 하다!
3. 2번 식을 미분하여 parameter(𝛾, 𝜙, 𝛼, 𝛽) optimization하기
- Derivative(Hessian matrix 포함)
- 𝛼 optimization 과정에서 Newton-Rhapson method 사용
<Learning parameters of the evidence lower bound>

ELBO로 파라미터를 최적화시키는 식이다.
- 𝛾, 𝜙, 𝛽 는 closed form으로 나타낼 수 있지만,
- 𝛼는 불가능하기에 open form으로써 iterative optimization을 진행한다
- 여기서 N-P method 활용된다.

이는 파라미터마다 최적화 시에 필요한 정보관계를 나타낸 것이다.
서로서로 상호연관이 되기에 coordinate update가 필요하다. 이는 Variational Inference 관점에서 두 가지로 나누어볼 수 있다.
- variational parameter 간의 내부 coordinate ascent
- variational param. 와 model param. 간의 외부 coordinate ascent
내부단계를 E, 외부단계를 M으로 보아 variational optimization의 EM 알고리즘으로도 볼 수 있다.
'심화 스터디 > 수리적 심화 머신러닝 & 생성모델 스터디' 카테고리의 다른 글
| Week 3 Gaussian Process (37~40) (0) | 2023.05.18 |
|---|---|
| [2주차 Forward, Rejection, Importance Sampling & Markov Chain, MCMC] - 목진휘 (0) | 2023.03.22 |
| [1주차 MLE, MAP & Entropy] - 목진휘 (0) | 2023.03.22 |
| [2주차 Hidden Markov Model Part1]- 박상준 (0) | 2023.03.20 |
| [1주차 K-mean clustering & Gaussian Mixture Model 신인섭] (0) | 2023.03.12 |





댓글 영역