고정 헤더 영역
상세 컨텐츠
본문
https://blog.naver.com/andrew9909 에도 동시에 글을 업로드하고 있습니다.
0. 들어가며

역대 ILSVRC 우승 모델들을 보면, 최대 22개의 층으로 구성되어 있는 것을 볼 수 있습니다. 2014년의 GoogleNet이 22개의 층을 가지는 것에 비교하면, ResNet은 152개의 층을 가져 약 7배나 깊어진 모습을 확인할 수 있습니다.

층을 깊게 한다는 것은 쉽게 말해 더 자세한 분석을 할 수 있도록 하지만, 기존 모델들이 층을 계속해서 깊게만 만들지 않은 데에는 이유가 있습니다.
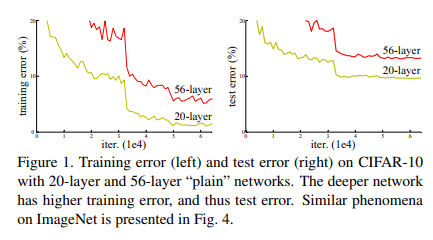
위 표를 보면, ResNet의 핵심 아이디어인 Skip Connection을 적용하지 않은 일반적인 네트워크에서, 20층으로 구성된 네트워크가 56층으로 구성된 네트워크보다 더 좋은 성능을 내는 것을 확인할 수 있습니다. 논문에서는 이를 degradation 문제라고 하고, 이는 gradient vanishing에 의해 발생됩니다. ResNet은 이를 skip connection을 이용해 해결하여 층을 깊게 하는 데 성공했습니다.
1. 모델 구조
①Skip Connection

사실상 논문의 가장 핵심 구조인 Residual Block입니다. 기존의 모델들이 계속해서 층을 통과시키기만 했다면, ResNet에서는 통과 후 input이었던 x를 결과에 더해줍니다.
y = F(x) + x
위 수식을 보면, x가 그대로 보존되므로 기존에 학습한 정보를 보존하고, 추가적으로 학습해야 하는 정보만을 학습합니다. 이 덕분에 연산량이 줄어들게 되는데요, 사람의 예로 설명하면, 1~10단원으로 구성되어 있는 책의 10단원에 대한 시험을 본다고 했을 때
1) 1~10단원에 대한 closed book 시험
2) 1~9단원까지는 open book, 10단원은 closed book 시험
기존까지 배웠던 정보에 대해서는 오픈 북으로 시험을 볼 수 있고, 이번에 배워야 할 내용에 대해서만 시험을 치르게 되는 경우 공부량이 줄어들게 될 것입니다. 이는 시험의 범위가 많아질수록 더욱 큰 차이를 낼 것입니다. ResNet이 층을 깊게 할 수 있었던 첫 번째 이유입니다.
두 번째로는, x가 그대로 보존되기 때문에 미분 시 '1'을 보장해줄 수 있습니다. 이를 통해 gradient vanishing 문제를 해결할 수 있습니다. ResNet이 층을 깊게 할 수 있었던 두 번째 이유입니다.
② 모델 전체 구조

모델 전체 구조는 VGG와 유사합니다. 맨 아래 그림이 VGG-19의 그림이고, 두 번째 그림이 거기에 층을 추가해서 만든 plain한 34층짜리 네트워크입니다. 이 두 번째 그림에 skip connection을 추가하여 Resnet을 구성했습니다. 처음을 제외하고는 균일하게 3x3 사이즈의 convolution filter를 사용했습니다. output size가 반으로 줄어들 때마다, feature map의 개수를 2배씩 늘렸습니다.
③ Bottleneck
1x1 conv를 사용해 더 적은 연산량을 만들고자 했습니다. bottleneck 구조라고 이름을 붙인 이유는 차원을 감소시켰다가 다시 증가시키는 모양이 병목과 비슷해서인데요, 왼쪽의 경우 파라미터 개수가 3 x 3 x 64 x 2 = 1152개이지만, bottleneck 구조를 활용한 오른쪽 그림의 경우 파라미터 개수가 (1 x 1 x 64) + (3 x 3 x 64) + (1 x 1x 256) = 896으로 연산량이 더 적어집니다.

2. 실험

top-1 error와 top-5 error 모두에서 다른 모델 대비 우수한 성능을 보이는 모습을 확인할 수 있습니다.

다음으로 plain 네트워크와 ResNet을 비교했는데, plain 네트워크의 경우 층이 깊어지면서 성능이 감소하는 모습을 확인할 수 있습니다. 이에 반해 ResNet은 층이 깊어질수록 성능이 잘 증가하고 있습니다.
참고자료)
원논문
https://deep-learning-study.tistory.com/473
https://velog.io/@lighthouse97/ResNet%EC%9D%98-%EC%9D%B4%ED%95%B4
'방학 세션 > CV' 카테고리의 다른 글
| [2주차 / 문성빈 / 논문리뷰] Deep Residual Learning for Image Recognition (1) | 2023.01.31 |
|---|---|
| [3주차 / 임정준 / 논문 리뷰] Fast R-CNN (0) | 2023.01.31 |
| [2주차 / 임채명 / 논문리뷰] Deep Residual Learning for Image Recognition (0) | 2023.01.31 |
| [2주차 / 임정준 / 논문리뷰] Deep Residual Learning for Image Recognition (0) | 2023.01.31 |
| [0주차 / 이름 / 논문리뷰] 논문명 (0) | 2023.01.29 |





댓글 영역