고정 헤더 영역
상세 컨텐츠
본문
Abstract
본 논문에서는 residual을 학습과정에서 사용하여('learning residual functions with reference to the layer inputs') 이전보다 더 깊은 신경망을 효과적으로 학습시키는 방법론을 제시하였습니다.
Introduction
신경망의 깊이는 이미지의 특징을 효과적으로 추출하여 학습하는 데에 있어 중요한 역할을 합니다. 그동안 ImageNet dataset에서 좋은 성능을 보인 모델들 모두 layer를 깊게 쌓아올렸습니다. 그러나 단순히 더 깊게 모델을 쌓는 것이 효과적이라고 할 수는 없습니다. 많은 layer를 학습하는 과정에서 흔히 겪을 수 있는 문제점은 '기울기 손실과 폭주(vanishing/exploding gradients)'입니다. 이는 normalized initialization과 모델 중간에 normalization layer를 추가하는 방식으로 다루어져왔습니다. 그러나 이러한 방안을 사용하여 네트워크가 converge하면 degradation 문제가 발생할 수 있습니다. degradation은 신경망이 깊어질수록 오히려 정확도가 급감하는 것입니다. 이는 오버피팅 문제가 아니라 training 과정에서부터 layer를 일정 수준 이상으로 깊게 쌓을 경우 training error가 높아지는 것을 말합니다. 이를 위한 해결책으로는 Identity mapping이 있고 본 논문에서는 Identity mapping을 활용하여 degradation 문제를 다루기 위한 방법으로 deep residual learning 프레임워크를 제안하고 있습니다.
Deep Residual Learning
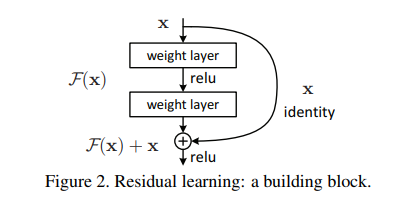
1. Residual Learning
x를 input으로 하여 H(x) 함수를 fit하는 기존의 신경망과는 달리, 해당 모델은 Shortcut을 사용한 Identity mapping을 통해 출력값에 x를 더하여 H(x) = F(x) + x 가 되고, 결국 original 함수인 H(x)가 아닌 residual 함수 F(x) = H(x) - x를 fit 하게 됩니다. 결국 residual를 최소화해야 하므로 F(x) = H(x) - x = 0이 되어야 하고, 결국 H(x) = x 즉, H(x)를 x로 mapping 하는 것이 목표가 됩니다. 해당 논문에서는 reference가 없이 새로운 함수를 학습해야 하는 기존의 모델보다 refence가 있는 residual mapping이 학습에 있어서 더 효과적일 것이라고 가정합니다.
2. Identity Mapping by Shortcuts
본 논문에서는 residual learning을 적용한 하나의 블록을 y = F(x, {W_i}) + x 라고 정의합니다. 여기서 x, y는 각각 input과 output을 의미하고 F(x, {Wi})는 학습되어야 하는 residual mapping을 의미합니다 (bias는 표기상 생략되었음). F + x의 과정은 shortcut connection과 element-wise 덧셈으로 수행됩니다. 따라서 파라미터 수나 계산 복잡도가 증가하지 않습니다. 또한 element-wise 덧셈을 하기 위해서는 F와 x의 차원이 동일해야 하는데 차원이 동일하지 않은 경우, 차원을 동일하게 해주기 위해 linear projection(W_s)을 추가해야 합니다. y = F(x, {W_i}) + W_sx
3. Network Architectures & Implementation
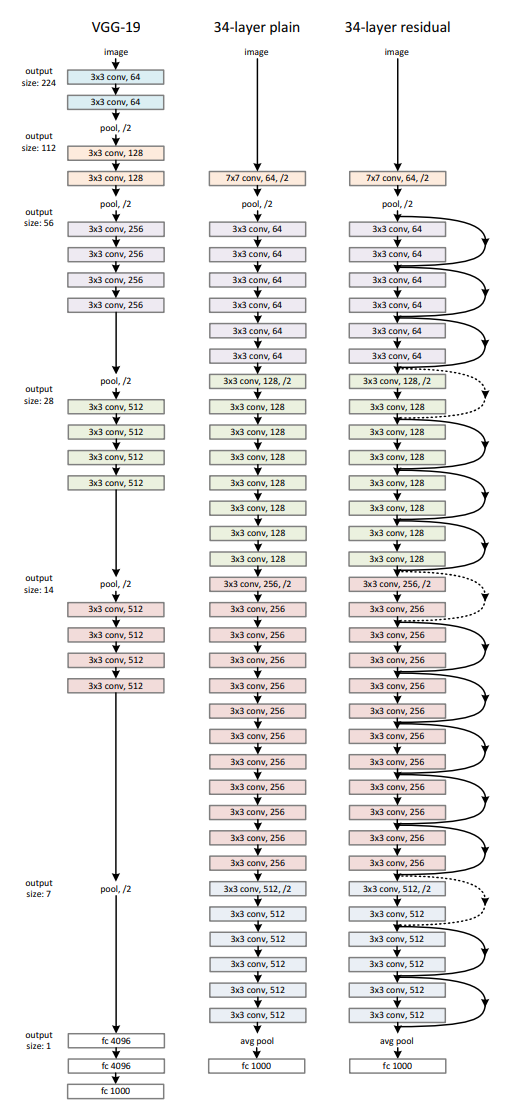
Plain Network는 구조상 두 가지 특징이 있습니다.
1. output size가 똑같은 경우 layer는 똑같은 수의 filter를 같습니다.
2. output size가 반으로 줄어든 경우 filter의 수를 두배로 하여 time complexity를 보존합니다.
ResNet의 기본 구조는 Plain network와 비슷하나 shortcut connection이 추가되었으며, 이때 점선으로 표기된 shortsut connection의 경우 차원이 증가하여 (1) zero padding을 하여 identity mapping을 하거나 (2) linear projection을 추가했음을 의미합니다.
Experiments
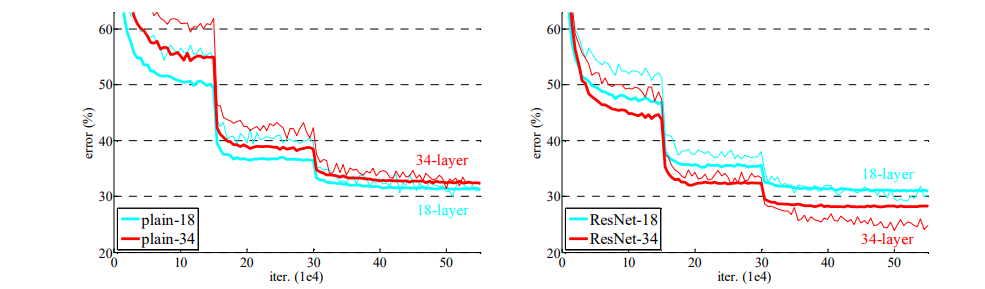
Plain network의 경우 18 layer를 사용했을 때보다 더 깊은 34 layer 모델이 항상 training error가 높음을 확인할 수 있습니다. plain network이 batch normalization을 사용하여 학습되었다는 점과 양호한 성능을 보이는 점을 고려하였을 때, 이는 vanishing gradients 때문이 아니라 degradation 문제임을 짐작할 수 있습니다. 반면, ResNet의 경우 34 layer를 사용했을 때 더 뛰어난 성능을 보이는 것으로 보아 degradation 문제가 해결됨을 확인할 수 있습니다. 또한 plain network와 비교하였을 때 ResNet이 더 좋은 성능을 보이는 것으로 보아 ResNet 구조가 깊은 신경망 학습에 있어 효과적임을 보여줍니다.
Deeper Bottleneck Architectures
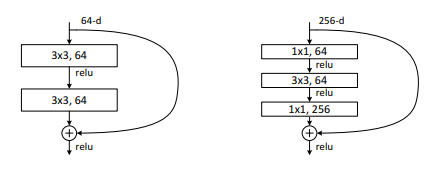
본 논문에서는 연산시간을 유지하면서 더 깊은 신경망을 쌓기 위해 블록을 bottleneck 구조로 구성하는 것을 제안합니다. 기존의 블록은 2개의 3x3 layer로 구성되었지만, bottleneck의 경우 1x1 layer를 3x3 layer 앞뒤로 추가하여 3x3 layer가 더 작은 차원의 연산을 수행하도록 해줍니다. 이때 time complexity를 보존하기 위해 shortcut은 항상 projection이 아닌 identity mapping(파라미터 수 유지)으로 연결되어야 합니다.
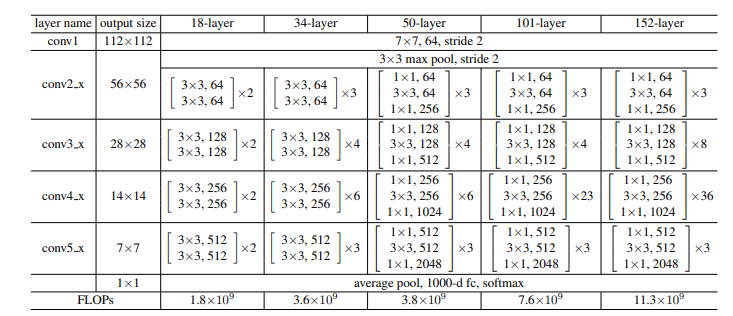
50-layer ResNet은 34-layer ResNet에 bottleneck block으로 수정한 것인데 신경망이 더 깊어졌음에도 불구하고 연산량은 비슷함(3.8 x 10^9 FLOPs)을 확인할 수 있습니다. 101-layer와 152-layer ResNet 또한 상당히 깊어졌음에도 VGG-16/19 모델보다 복잡성이 더 낮았으며 degradation 문제가 나타나지 않았습니다.
Conclusion
본 논문에서는 degradation 문제없이 더 깊은 신경망도 효과적으로 학습할 수 있는 방법으로 ResNet 모델을 제안하였습니다. Residual learning과 Shortcut connection을 통해 H(x)를 x에 mapping 하는 형태로 학습을 진행할 수 있게 되었으며, 더 깊은 모델을 쌓기 위해 bottleneck 구조도 적용하였습니다. 직관적인 아이디어를 통해 뛰어난 성능 향상을 이끌어냈다는 점이 놀랍고 재밌었습니다.
'방학 세션 > CV' 카테고리의 다른 글
| [2주차 / 문성빈 / 논문리뷰] Deep Residual Learning for Image Recognition (1) | 2023.01.31 |
|---|---|
| [3주차 / 임정준 / 논문 리뷰] Fast R-CNN (0) | 2023.01.31 |
| [2주차 / 진유석 / 논문리뷰] Deep Residual Learning for Image Recognition (0) | 2023.01.31 |
| [2주차 / 임정준 / 논문리뷰] Deep Residual Learning for Image Recognition (0) | 2023.01.31 |
| [0주차 / 이름 / 논문리뷰] 논문명 (0) | 2023.01.29 |





댓글 영역