고정 헤더 영역
상세 컨텐츠
본문 제목
[논문 리뷰 스터디] DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
본문
이 논문은 2018년에 OpenAI에서 물리 기반 강화학습을 연구하여 낸 논문이며, 실제로 저자인 Xue bin peng은 이 분야의 저명한 연구자로 AMP, ASE와 같은 영향력 있는 후속 논문을 냈습니다. 그 중 AMP는 Nvidia가 최근에 낸 Isaac이라는 시뮬레이터를 공개할 때 같이 예시로 공개된 모델이기도 합니다.

1. Introduction
사람의 움직임을 익히도록 NN을 학습하는 방법은 예전부터 많았습니다. 이 방법은 몸의 무게중심의 위치, 이동거리 등의 보상을 주어 학습을 진행하는데, 이 reward가 사람의 직관에 따른다는 단점이 있습니다. 또한, 학습이 잘 진행되지 않아 우스꽝스러운 모습을 연출하기도 했습니다.
DeepMimic은 Motion Capture Data(MoCap)를 통해 사람의 움직입에 따르도록 학습시키는 방법을 채택하고 있습니다. 이 학습의 결과로 얻는 network는 가상환경 속에서 사람의 Dynamics를 얻는 것입니다.
Dynamic를 얻는 것에는 수식 기반 algorithm과 MoCap 기반 algorithm이 있는데, 둘 다 사용하면 행위에 비해 많은 Joints를 지닌 인간의 행동을 재현하기에는 힘이 들고, 수식 기반 algorithm을 사용하면 model별로 각각 계산을 진행해야하고, MoCap기반 algorithm을 사용하면 매번 해당 모션을 취득해야만 했습니다. 결국 다시 말하자면 “Walk”라는 행동의 본질이라는 것은 매우 복잡한 것입니다. 이를 Neural Network를 도입하여 해결하려는 것입니다.
DeepMimic의 Contribution은 크게 3가지로 볼 수 있습니다.
- Example-based Deep RL을 사용하여 physics-based animation이 가능하게 했습니다. 이에 캐릭터가 다양한 동작을 학습, 외부 요인에 대응하였고 실제로 반응할 수 있도록 만들었습니다. 이전에는 주로 사람이 수동적으로 캐릭터를 제어하는 방식이 주를 이루었지만 DeepMimic은 강화학습을 통해 캐릭터가 스스로 움직임을 학습하도록 만들었습니다.
- 한 가지의 캐릭터에만 작동하는 것이 아니라 여러 캐릭터에 작용하며, 물리 엔진(Mujoco etc..)와 함께 사용할 수 있습니다.
- 복잡하고 고도로 동적인 기술을 학습시킬 수 있습니다. 이에 캐릭터가 고난도 동작을 수행하고, 예기치 않은 상황에서도 실제적으로 대응할 수 있게 됩니다.
2. Policy Representation
DeepMimic은 여러가지 RL methods를 사용할 수 있는데, LSTM + DDPG + PPO를 대표적으로 사용하였습니다.
Reinforcement Learning에는 Env와 Action으로부터 reward를 얻는 Value-based training과 Env로부터 action을 연결하는 network를 학습하는 Policy-based training이 존재하는데 전자의 방식은 reward가 중심이 되어 학습이 진행되므로 Action이 급작스럽게 바뀔 수 있으므로 사람의 움직임을 학습하는데 적합하지 않습니다. 이에 Policy-based methods 중에 가장 유명한 PPO를 사용하는 것입니다.
2.1 States and Actions
States는 각 link의 상대적인 위치, 회전, 선형 및 각속도를 포함하는 로컬 좌표계에서 계산되고, 시간에 따라 변화하는 목표 자세를 반영하기 위해 위상 변수가 포함됩니다.
Actions는 policy를 통해서 결정됩니다. Policy는 현재 상태를 입력을 받고 적절한 행동을 출력하는 함수입니다.
2.2 Network
LSTM + DDPG
LSTM : Sequence data를 처리하는데 효과적이며 캐릭터의 움직임을 제어하기 위해 사용됩니다. 현재 상태와 목표 자세를 입력 받아 다음 행동을 출력합니다.
DDPG : 연속적인 행동 공간에서 Policy를 학습하는데 사용됩니다. 현재 상태를 입력으로 받아 연속적인 행동 공간에서 적절한 행동을 선택합니다.


2.3 Reward
Total reward

The imitation objective

Pose reward : joint orientation quarternions difference

Velocity reward : local joint angular velocities difference

End-effecter reward : character’s hands와 reference motion의 포지션 사이 difference
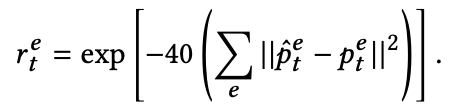
Center-of-mass reward : penalizes deviations in the character’s center-of-mass

3. Training
3.1 Initial State Distribution
- Initial state distribution $p(s_0)$은 agent가 각 episode가 시작하는 상태를 결정합니다.
- Problem : 보통은 Initial state distribution을 fixed state → convenient
- Earlier phases에서 제대로 learning하지 못하면 later phases에서 진행이 잘 되지 않습니다. → backflip에서 landing은 중요한 과정인데, jumping했을때 land를 잘 못하면 reward를 잘 안 주게 됩니다.
- Reward를 retrospectively하게 받기 때문에 high-reward state를 가기 전에 선호도를 알기 힘듭니다.
- 각 episode의 시작에서, state는 reference motion으로 부터 sampled되고, agent의 state를 initialize하는데 사용됩니다. → RSI
- Jump같은 경우 많은 전략들이 실패로 이뤄질 것이고 이에 성공적인 flip과 같은 경우는 나오지 않을 수도 있다.
- Reference motion의 info에 접근할 수 있는 또다른 방법으로 사용됨.
3.2 Early Termination
Training할 때는 episode가 finite horizon입니다.
Early Termination은 이미 존재했지만, 종종 performance에 영향을 미쳤다고 평가되지는 않았습니다. 이 연구에서는 특정 links가 땅에 닿으면 episode가 끝나도록 설정됩니다.
Advatages
- ET가 발생하면 episode의 나머지에서 zero reward이고, 이는 reward function이 불필요한 행동을 피하도록하게 만들어지도록 합니다.
- Task에 더 관련 있는 samples로 data distribution이 편향되도록 하는 curating mechanism역할입니다.
ET가 없으면 초기 단계에서 data가 넘어짐이나 좋지 않은 데이터로 지배될 가능성이 높습니다.
4. Multi-Skill Integration
- Multi-Clip Reward
1. Simply max over
2. 목적은 policy가 주어진 상황에 가장 적절한 clip을 고르는 flexibility를 제공하고, kinematic planner없이 적절한 clip들 사이에 바꿀 수 있는 능력을 제공하는 것입니다. - Skill Selector
1. 주어진 시간에 user가 clip을 통제하는 능력입니다.
2. 동시에 여러개의 skills로 이루어진 set을 imitate하도록 policy를 train하고, 한 번 train하면 필요할 때 임의의 sequence of skills를 실행할 수 있게 됩니다. - Composite Policy
이는 여러 기술에 대한 network를 묶어 정해진 traget을 위한 가장 높은 reward를 낼 수 있는 network를 이용하는 방법입니다.
1. skills의 수가 증가하면 당연히 policy가 learning하기 어려워집니다. → divide-and-conquer → seperate polices가 다른 skills를 실행하도록 train되고, composite policy로 통합됩니다 → Boltzman distribution → expected value가 높을수록 더 선택될 확률이 높습니다.
2. 반복적으로 composite policy를 sampling하면 charater가 추가적인 training 없이 sequence of skills를 실행할 수 있게 됩니다.
5. Tasks


참고문헌





댓글 영역