고정 헤더 영역
상세 컨텐츠
본문 제목
[논문 리뷰 스터디] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
본문

작성자: 17기 황민아
1. Introduction
Vision-language pre-training(VLP)은 최근 다양한 멀티모달 task에서 높은 성능을 보이고 있으나, 두 가지 한계가 존재한다.
Model Perspective
대다수의 VLP 모델은 encoder-based 혹은 encoder-decoder 모델 구조를 갖는다. 하지만
- Encoder-based 모델은 text generation task(image captioning,…)에 직접적으로 적용되기 어렵다.
- Encoder-decoder 모델은 image-text retrieval task에서의 성능이 떨어진다. (두 modality간의 understanding이 필요한 task에 약하다.)
Data Perspective
대부분의 SOTA 모델들(CLIP, ALBEF, SimVLM)은 웹 상에서 수집된 image-text pair로 학습이 된다. 데이터셋의 크기를 증폭시켜 학습함에 따라 성능 향상이 이루어졌으나, 이 논문에서는 데이터 자체에 대한 의문을 제기한다. Vision-language learning에 있어 noisy web text를 사용하는 것은 최적이 아닌, 차선책이라는 것이다.
이러한 한계를 넘어서고자 이 논문에서는 BLIP이라는 새로운 VLP 프레임워크를 제시한다. BLIP은 모델의 관점, 그리고 데이터의 관점 모두에서 contribution을 보인다.
Multimodal mixture of Encoder-Decoder(MED)
더 효과적인 multi-task pre-training과 유연한 transfer learning을 위해 새로운 모델 구조를 제시한다. 단순한 encoder 혹은 encoder-decoder 구조가 아닌, unimodal encoder, image-grounded text encoder, image-grounded text encoder 구조를 제시한다.
Captioning and Filtering(CapFilt)
Noisy image-text pair로부터 데이터셋을 bootstrapping하여 학습하는 방법을 제시한다. Pre-trained된 MED을 finetuning하여 웹 이미지에 대한 synthetic caption을 생성하는 captioner와 original web text와 synthetic text에서 noisy caption을 제거하는 filter를 만든다.
2. Method
Model Architecture
Understanding과 Generation 모두에 능한 모델을 학습시키기 위해 MED(Multimodal mixture of Encoder-Decoder) 구조를 제안한다.

(1) Unimodal encoder: 이미지와 텍스트를 각각 인코딩하며, Image encoder로는 ViT를, text encoder로는 BERT를 사용한다.
(💡 ViT: Input image를 patch로 나누고 [CLS] token을 추가하여 embedding한 후 encoding하는 모델. 최 다양한 연구에서 많이 사용되고 있다.)
(2) Image-grounded text encoder: Self attention layer와 feed forward network 사이에 Cross Attention layer를 추가하여 이미지에 대한 시각적 정보를 넣어준다.
(3) Image-grounded text decoder: Image-grounded text encoder에서 Bidirectional self-attention layer를 causal self-attention layer로 대체한 구조이다.
Pre-training Objectives
총 세 가지 목적식을 동시에 최적화한다.
(1) Image-Text Contrastive Loss (ITC):
Unimodal encoder를 학습하는데 사용한다. Visual transformer과 text transformer 간의 feature space의 정렬에 있어 positive pair는 가깝게, negative는 멀리 위치하게끔 encoder를 학습시킨다. 다른 VLP에서 진행되는 contrastive learning 과정과 동일하며, vision과 language understanding을 높이기 위한 과정이다.
(2) Image-Text Matching Loss (ITM):
Image-grounded text encoder를 학습하는데 사용한다. ITM은 head(linear layer)를 통해 image-text pair가 positive인지 negative인지 분류하는 binary classification task이다. 이 때 negative pair로 분류되는 경우, image와 text간의 유사도에 따라 loss에 반영되는 가중치를 조정한다. (분류의 난이도를 반영하기 위해) 마찬가지로 vision-language understanding을 위한 과정이다.
(3) Language Modeling Loss (LM):
Image-grounded text decoder를 학습하는데 사용한다. Autoregressive한 방법으로 텍스트의 Cross entropy loss를 최적화시킨다. MLM loss에 비해 이미지에 대한 caption을 생성하는 성능을 높여준다.
(💡 MLM: Masked Language Model. 양방향 정보(과거, 미래)를 고려
Autoregressive: 과거 정보를 고려)
추가적으로 text encoder와 text decoder의 파라미터를 Self Attention layer는 제외하고 공유하게끔 하 pre-training의 효율성을 높였다.
SA layer를 제외하는 이유는 해당 레이어에서 encoding task와 decoding task의 차이가 가장 잘 반영되기 때문이다. Encoder의 경우 bi-directional self-attention을 통해 representation을 뽑아내야 하지만, decoder의 경우 causal - 인과적인 관계를 반영하여 다음 token을 예측해야 한다. 반면 CA, FNN는 image grounding 역할을 하기에 encoder, decoder에서 역할의 큰 차이가 없다.
CapFilt
Image-text pair를 사람이 생성하는데는 많은 Annotation cost가 들어가기에, 그 대안으로 최근의 연구는 web에서 crawling된 대량의 Image-alt-text pair를 사용한다.
*Alt-text: 브라우저가 이미지를 렌더링 하지 못할 때 웹 페이지에 표시되는 이미지에 대한 설명
하지만 alt-text는 이미지에 대한 충분하거나 정확한 설명을 제공하지 못하는 경우가 많고, 이는 vision-language alignment를 학습하는데 있어 noisy signal을 만들어낸다.
따라서 이 논문에서는 text corpus의 품질을 높이기 위해 CapFilt라는 방법론을 제시한다.
CapFilt는 Captioner와 Filter로 구성되며, Captioner는 이미지로부터 caption을 생성하는 역할, filter는 caption의 noisy signal을 필터링하는 역할을 한다.

두 모듈은 같은 pre-trained MED를 finetuning하여 만들어진다
- Captioner로는 image-grounded text decoder를 사용하며 LM objective를 통해 finetuning된다.
- Filter로는 image-grounded text encoder로 ITC, ITM objective를 통해 finetuning된다.
Finetuning 과정에서는 small-scale human-annotated image-text pair ($I_h, T_h$)를 사용한다.
Captioner는 Web image $I_w$가 주어졌을 떄 synthetic caption $T_s$를 생성한다.
Filter는 기존의 web text $T_w$와 captioner에서 생성된 synthetic caption $T_s$에서 noisy text를 제거한다. 주어진 text에 대해 ITM head가 이미지와의 matching을 negative라고 예측하면 그 text는 noisy text로 간주한다.

결과적으로는 captioner와 filter를 모두 거친 web image-text pair, filter만을 거친 web image-text pair, 그리고 human-annotated image-text pair를 얻게 된다. 이 세 종류의 pair들을 합쳐 새로운 데이터셋을 만들고, 이를 새로운 모델을 pre-training하는데 활용한다.
3. Experiments and Discussions
Pre-training Details
- Image transformer: ViT pre-trained on ImageNet
- ViT-B/16
- ViT-L/16
- Text transformer: BERT base
- 20 epoch, batch size 2880(ViT-B)/2400(ViT-L), AdamW optimizer
Effect of CapFilt

Down-stream task에 있어 Captioner와 Filter를 모두 적용하는 것이 original noisy web text를 사용하는 것보다 성능이 향상됨을 확인할 수 있다.
또한 더 큰 데이터셋과 더 큰 vision backbone을 사용하거나, base보다 더 큰 ViT-L을 활용하여 captioner와 filter를 구성하는 경우 성능이 더 향상되었다.
Comparison with SOTA
BLIP은 Image-text retrieval, Image captioning, VQA 세 가지 task에서 기존 SOTA보다 높은 성능을 보였다.
Image-text retrieval
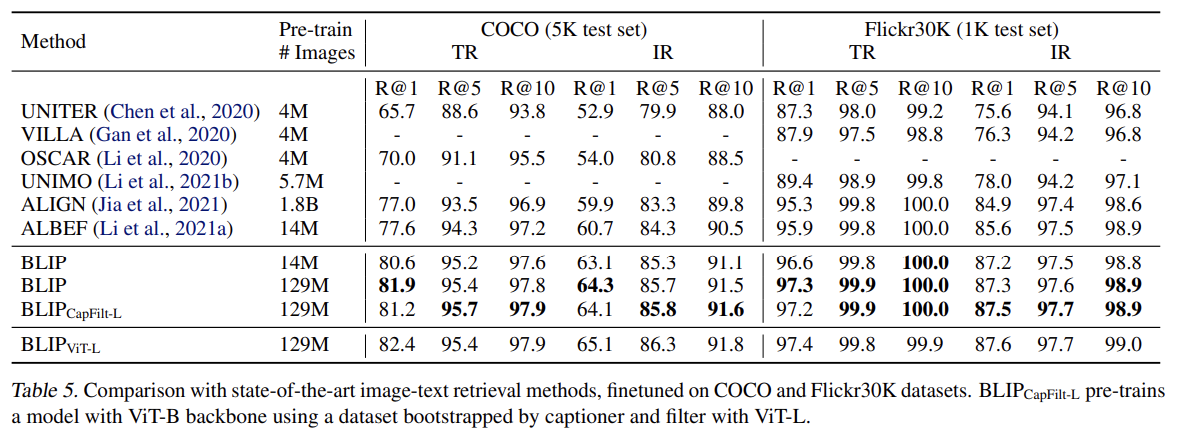
Image Captioning

VQA

4. Conclusion
이 논문은 CapFilt 구조를 통해 데이터셋의 품질을 높이고, 이를 multimodal mixture of encoder-decoder model의 pre-training에 활용함으로써 다양한 VL task에 대해 높은 performance를 보이는 BLIP 모델을 제시하였다. 많은 task에서 SOTA를 달성하였으며 특히 Image Captioning, VQA에 있어서는 더 적은 데이터셋을 사용했음에도 좋은 성능을 보였다.
논문에서는 BLIP의 성능향상을 위해 다음과 같은 여지를 남긴다.
- Dataset Bootstrapping 과정을 반복하여 데이터의 품질을 더 높인다
- 이미지 당 synthetic caption의 수를 늘려 pre-training corpus의 크기를 키운다.
- Model ensemble
하지만 BLIP은 모델 구조가 복잡하며, end-to-end 구조로 인해 pre-training 과정에서 많은 연산량이 요구된다는 한계가 있다.
이러한 한계점을 보완하기 위해 2023년 3월, BLIP2 모델이 공개되었다.(Frozen image encoder와 LLM 모델을 연결해주는 방법론을 이용하는 방식)






댓글 영역