고정 헤더 영역
상세 컨텐츠
본문
작성자: 17기 김희준
본 포스팅은 “실전 시계열 분석(에일린 닐슨 저)” 교재를 바탕으로 작성되었습니다.

2장 시계열 데이터의 발견 및 다루기
2-1. 시간과 관련되어야만 시계열 분석을 적용 할 수 있을까?
NO. 와인 데이터셋은 빛의 파장 대 강도에 대한 그래프로 시간의 흐름과는 전혀 상관이 없지만, X축은 유의미한 방식으로 정렬되어 있고, 그 거리는 구체적인 의미를 갖기에 시계열 분석을 적용할 수 있다.
2-2. 시계열 분석이 적용될 수 있는 케이스
1. 타임스태프가 기록된 경우
2. 명시적으로 타임스태프는 없지만, 변수 중 하나를 일정한 간격의 시간에 대응할 수 있는 경우
3. 의학, 청각학, 기상학 등 과학 학문 분야에서 물리적 흔적이 단일 벡터와 같은 형태로 저장되는 경우
2-3. 사전관찰(look-ahead)
데이터를 통해 실제로 알아야 하는 시점보다 더 일찍 미래에 대한 사실을 발견하는 경우로서, data leakage와 유사한 개념이다.
하지만 사전관찰을 확정 진단하는 통계 방법은 존재하지 않기에 끊임없이 예의주시해야 한다. 다음은 사전관찰을 방지할 수 있는 여러 팁들이다.
- 매우 적은 데이터셋으로 처리의 전체 과정을 구축해보기
- 각 타임스태프와 관련된 지연이 무엇인지 확인하기
- 시간을 인식할 수 있는 에러 검사 또는 교차검증을 사용하기
- 의도적으로 사전관찰을 도입하여 모델 정확도에 생기는 변화를 체감하기
2-4.결측데이터 다루기
- 포워드필(forward fill): 누락된 값이 나타나기 직전의 값으로 누락된 값을 채우는 가장 간단한 방법
- 이동평균(moving average): 이전의 값들에 대한 평균으로 누락된 값을 채우는 방법
- 선형 보간법(linear interpolation): 누락된 값이 주변 데이터에 선형적인 일관성을 갖도록 제한하는 방법 -> 사전관찰의 문제가 있을지도.
2-5. 업샘플링과 다운샘플링
- 다운샘플링: 데이터의 빈도를 줄이는 방법이다. 예를들어 2000년 1월~ 2010년 12월까지 매월 데이터가 존재할 때, 매년 1월의 데이터만 추출하는 식으로 다운샘플링할 수 있다.
- 업샘플링: 불규칙적으로 샘플링된 시계열을 규칙적으로 변환하거나, 특정 모델이 현재 보유한 데이터보다 더 높은 빈도를 요구하는 경우, 빈도를 높이는 방법이다. 이 때 새로운 정보를 생성하는 것이므로 사전관찰에 주의해야 한다.
2-6. 데이터 평활(smoothing)
평활이란 시간에 따라 생긴 무작위적 변화로 생기는 효과를 줄이는 기법이다.
- 지수 평활(exponential smoothing): 모든 시점의 데이터를 똑같이 취급하는 것이 아니라, 더 최근 데이터일수록 많은 가중치를 주어 더 잘 인식하도록 만드는 방법이다.
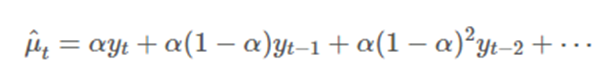
위 식의 α가 지수적으로 감소하는 가중치이다. 즉, 최근의 값에 더 큰 가중치가 매겨진 현재와 과거 관측값들의 선형결합으로 표현된다.
2-7. 계절성 데이터
데이터의 형태가 일정한 주기에 따라 안정적으로 반복해서 나타나면 계절성 데이터라고 부를 수 있다. 순환성 데이터는 반복적인 동작을 보이긴 하나, 기간이 가변적이라는 점에서 계절성 데이터라 볼 수 없다. 예컨대, 주식시장의 호황과 불황의 주기처럼 불확실한 기간 말이다.

참고)
시계열의 4가지 요인
(1) 추세 요인 (Trend factor)은 인구의 변화, 자원의 변화, 자본재의 변화, 기술의 변화 등과 같은 요인들에 의해 영향을 받는 장기 변동 요인 으로서, 급격한 충격이 없는 한 지속되는 특성이 있다. "10년 주기의 세계경제 변동 추세" 같은 것이 추세 요인의 예라고 할 수 있다.
(2) 순환 요인 (Cycle factor)은 경제활동의 팽창과 위축과 같이 불규칙적이며 반복적인 중기 변동요인 을 말한다. 주식투자가들이 "건설업/반도체업/조선업 순환주기"를 고려해서 투자한다고 말하는게 좋은 예다.
만약 관측한 데이터셋이 10년 미만일 경우 추세 요인과 순환 요인을 구분하는 것이 매우 어렵다. 그래서 관측기간이 길지 않을 경우 추세와 순환 요인을 구분하지 않고 그냥 묶어서 추세 요인이라고 분석하기도 한다.
(3) 계절 요인 (Seasonal factor)은 1년의 주기 를 가지고 반복되는 변화를 말하며, 계절의 변화, 공휴일의 반복, 추석 명절의 반복 등 과 같은 요인들에 의하여 발생한다.
(4) 불규칙 요인 (Irregular / Random factor, Noise)은 일정한 규칙성을 인지할 수 없는 변동의 유형을 의미한다. 천재지변, 전쟁, 질병 등과 같이 예 상할 수 없는 우연적 요인에 의해 발생되는 변동을 총칭한다. 불규칙변동 은 경제활동에 미미한 영향을 미치기도 하지만 때로는 경제생활에 지대한 영향을 주기도 한다.
출처: https://rfriend.tistory.com/509
[Python 시계열 자료 분석] 시계열 구성 요인 (Time series component factors): 추세(trend), 순환(cycle), 계절(s
그동안 여러 포스팅에 나누어서 Python pandas 라이브러리에서 사용할 수 있는 시계열 데이터 처리 함수, 메소드, attributes 들에 대해서 소개했습니다. 이번 포스팅에서는 시계열(Time series)의 4가지
rfriend.tistory.com
3장 시계열의 탐색적 자료분석
이 장의 전반부는 시계열에서 유용한 상관관계 파악 방법들을 소개하고, 후반부는 EDA에 대해 소개하고 있다. EDA 부분은 코드가 전부 R이기도 하고, 보다 개념적인 부분에 초점을 맞추고 싶은 생각에 전반부만 내용정리를 하였다.
3-1. 시계열에서 상관관계를 파악할 때 주의할 점!

위 사진은 특정 시간에 대한 두 주식의 관계를 나타낸 산점도, 두 주식의 시간에 따른 각각의 가격 변동이 갖는 연관성이다. 사진만 봐서는 명백한 상관관계라 볼 수 있지만, 이것이 수익을 낼 수 있는 상관관계라 보기엔 무리가 있다. 투자를 해서 수익을 내기 위해선 동시간대의 두 주식의 상관관계를 볼 것이 아니라, 시간상 먼저 알게 된 한 주가의 변동이 나중 시간대의 다른 주가의 변동에 어떤 영향을 주는지 봐야하기 때문이다. lag() 함수를 사용하여 한 주식의 시간대를 앞당겨주면 아까와 사뭇 다른, 상관관계가 없는 산점도가 그려진다. 아래 그림처럼 말이다.

3-2. 정상성(stationary)
정상성이란 시계열의 특징이 관측된 시간과 무관하다는 의미이다. 즉, 추세나 계절성이 있는 시계열은 정상성을 나타내는 시계열이 아니다.

위 9개 그래프 중 정상성을 나타내는 시계열을 찾아보자. 보통 비정상성을 띠는 시계열을 배제하는 소거법이 유용하다. 분명히 계절성이 있는 d, h, i는 정상성이 없다. a,c,e,f,i는 추세가 있고 수준이 있기에 정상성이 없다. 분산이 증가하는 i도 후보가 되지 못한다.
g는 주기를 보이는 것 같지만, 주기 자체가 불규칙적이기에 정상 시계열이고, b 역시 일정한 분산을 갖고 평평한 그래프를 띠므로 정상 시계열이다.
하지만 이렇게 눈대중으로 정상성을 확인하는 것은 부정확하다. 이 방법보단 단위근(unit-root) 검정을 사용한다. 이 중 대표적인 것이 ADF(Augmented Dicky-Fuller) 검정이다. ADF 검정의 귀무가설은 '시계열에 단위근이 존재한다'이다.

위 식이 ADF 검정의 틀로서, y_(t-1)의 파라미터가 0인지에 대한 t검정을 실시한다.
몇 가지 간단한 변환으로도 시계열을 정상화할 수 있다. 분산이 변화하는 경우에는 로그와 제곱근을 이용하여 변환을 하고, 추세는 차분을 구하여 제거한다.
3-3. 자기상관(autocorrelation)
자체상관은 특정 시점의 값이 다른 시점의 값과 상관관계가 있다는 의미이다. 이 자체상관을 특정 시점에 고정되지 않고 일반화한 개념이 자기상관이다. 예컨대 5월 1일의 주식 가격이 6월 1일의 주식 가격과 높은 상관관계를 갖는 것이 자기상관관계이다.
서로 다른 변수의 상관관계에 관심을 갖는 회귀분석의 아이디어와 달리, 자기상관함수는 하나의 변수를 놓고 시차에 대한 함수로 표현한다. 한 변수의 시점을 shift한 것들에 대한 함수라는 뜻이다. 아래는 자기상관함수의 수식이다.


위의 함수는 사인함수이고, 밑의 함수가 자기상관함수이다. 자기상관함수의 x축은 시차를 의미하는데, 시차가 0이면 상관관계는 1이고(시차가 0이라는 건 자기 자신과의 관계를 의미하니 1이 나온 것은 당연한 결과이다.) 시차가 1이면 상관관계가 0.5, 시차가 2이면 -0.5인 것을 알 수 있다.
3-4. 편자기상관함수(Partial Auto Correlation Function)
만약 t시점과 t-2시점 사이에 존재하는 t-1시점의 영향을 제거하고 싶다면 어떻게 해야할까? 이 질문에 대한 해답이 편자기상관함수(PACF)이다. t시점과 t+k시점 사이에 k-1개의 값들의 영향력을 배제하고 측정한다. 두 지점 사이의 조건부 상관관계를 계산하고 이를 제거해주는 작업을 거치기에 자기상관함수보다 훨씬 복잡한 절차를 거쳐야 한다.


e_t는 y_(t-1)부터 y_(t-(k-1))로 설명되는 부분을 제거한 것이고, e_(t-k)도 마찬가지다. 그러니 온전히 y_t와 y_(t-k)와의 관계만 본다는 의미이다.

위 그림을 보면 위의 그래프는 사인함수이고, 밑의 그래프는 PACF이다. 앞선 ACF와 달리 불필요한 중복관계를 제거하고 정말 유용한 정보만 남긴다.
'심화 스터디 > 시계열 분석 스터디 (feat.금융)' 카테고리의 다른 글
| [시계열 스터디 2주차(엄기영)] (0) | 2023.03.16 |
|---|---|
| 시계열 스터디 2주차(조성윤) (0) | 2023.03.16 |
| 시계열 스터디 2주차(김태영) : 시계열 통계모델1 [이론] (0) | 2023.03.14 |
| [시계열 스터디 1주차(조성윤)]: 2장 Review (0) | 2023.03.09 |
| [시계열 스터디 1주차(엄기영)] (0) | 2023.03.09 |





댓글 영역