고정 헤더 영역
상세 컨텐츠
본문
Introduction
딥러닝은 자연이미지, 음성을 포함한 오디오 파형, 자연어 말뭉치와 등의 데이터에 대한 확률 분포를 표현하는 rich, hierarchical한 모델을 발견하게 해준다. 지금까지 가장 성공적인 부분은 discriminative model, 주로 고차원의 입력을 특정 class label로 매핑해주는 모델과 관련이 있다. 해당 모델은 piecewise linear unit를 사용한 역전파 기법과 드롭아웃 알고리즘를 기반으로 성능을 낼 수 있었다.
반면, 다루기 힘든 probabilistic computation의 추정의 어려움, piecewise linear unit의 적용의 어려움으로 deep generative model은 큰 성과를 내지 못하였다. 이에 따라 해당 논문은 새로운 generative model 측정 절차 - adversarial nets framework를 제시한다.
Adversarial nets framework에서 generative model은 discriminative model과 겨루는 적대적 학습을 한다.
- Discriminative 모델은 샘플이 생성 모델이 만들어낸 데이터인지, 실제 데이터인지를 구별한다.
- Generative 모델은 discrimiative 모델을 속이기 위해 실제 데이터와 유사한 데이터를 생성한다.
적대적인 구조를 통해 두 모델은 경쟁을 하게 되고, 이를 통해 성능 향상이 이루어진다. 이 일련의 과정은 generative 모델이 실제와 구별할 수 없는 데이터를 만들 때까지 계속된다.
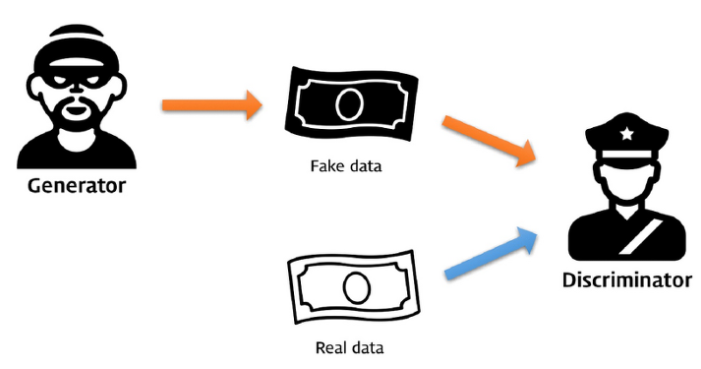
본 논문에서 generative model은 random noise를 multilayer perceptron에 넣어 샘플을 생성하며, discriminative model 또한 multilayer perceptron의 형태이다. 두 모델 모두 역전파와 드롭아웃 알고리즘만을 통해 학습시킬 수 있으며, 순전파만을 통해 generative model에서 샘플링을 할 수 있다. Approximate inference나 Markov chain은 필요하지 않다.
Adversarial nets
데이터 $ x $에 대한 generator의 분포 $ p_g $를 학습하기 위해 먼저 input noise 변수의 분포 $ p_z(z) $, 그리고 이 noise 변수를 data space에 매핑해주는 함수 $ G(z;\theta_g) $를 정의한다. $ G $는 parameters $ \theta_g $를 갖는 multilayer perceptron이며, 미분가능하다.
또다른 multilayer perceptron $ D(x;\theta_d) $도 정의한다. $ D(x) $는 $ x $가 $ p_g $가 아닌 실제 데이터셋에서 왔을 확률을 나타낸다.
$ D $를 학습시켜 실제 학습 데이터셋과 $ G $에서 샘플링한 데이터에 정확한 label을 할당할 확률을 최대화하고, 동시에 $ G $를 학습시켜 $ log(1-D(G(z))) $를 최소화하는 것이 최종적인 목표이다. 다음과 같은 식으로 표현 가능하다.

첫번째 항은 실제 데이터를 discriminator에 넣었을 때 나오는 결과에 대한 log expectation, 두번째 항은 generator에서 생성된 데이터를 discriminator에 넣었을때 결과에 대한 log(1-x) expectation이다.
결국 $ D $와 $ G $는 value function $V(G, D)$의 two-player minimax game을 한다고 할 수 있다.
학습과정은 다음과 같다.

해당 프레임워크를 실제로 적용하기 위해서는 iterative, numerical한 접근법을 도입해야한다. 학습 과정의 inner loop에서 D를 완전히 최적화하는 것은 계산적으로 불가능할 뿐더러 유한한 데이터셋에서는 overfitting으로 이어질 수 있다.
따라서 본 논문에서는 k steps of optimizing D, 1 step of optimizing G 과정을 반복한다. G가 충분히 천천히 변화한다는 가정 하에 D는 항상 최적해에 가깝게 유지된다. 해당 과정은 다음과 같이 Algorithm 1으로 표현할 수 있으며, 본 논문에서는 k=1로 설정하고 실험을 진행하였다.

Theoretical Results
Generator $ G $는 $ z ~ p_z $ 일 때 샘플 G(z)의 분포를 확률분포 $ p_g $로 정의한다. 따라서 충분한 capacity와 학습시간이 있다면 Algorithm 1이 $p_{data}$에 수렴하게 만들고자 한다.
본 논문에서는 minimax game이 $ p_g = p_data $일 때 global optimum을 가지며, Algorithm 1이 value function V(G,D)를 최적화시켜 최종적인 결과를 얻게됨을 아래와 같은 과정을 통해 증명한다.
Global Optimality of $ p_g = p_{data} $
첫번째로 어떤 주어진 generator $ G $에 대한 최적의 discriminator $ D $에 대한 proposition이다.
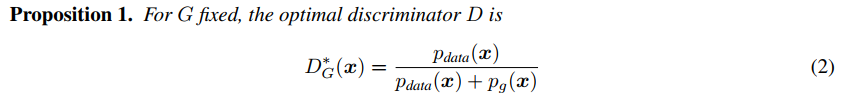
증명은 다음과 같다.

${0, 0}$이 아닌 $ (a, b) \in \mathbb{R^2} $ 에 대해 함수 $ y \rightarrow a log(y) + b log(1-y) $ 는
[0, 1] 내의 범위에서 a/{a+b} 일 때 최댓값을 갖는다.
따라서 기존의 minimax game의 목적식은 다음과 같이 다시 쓰일 수 있다.

Theorem 1에 의하면

C(G)의 global minimum은 $p_g = p_{data}$에서 나오며 이 때의 C(G) 값은 $-log4$이다.
Experiments
MNIST, TFD, CIFAR-10 데이터셋으로 학습을 진행하였다. Generator net은 rectifier linear activation과 sigmoid activation을 혼합하여 사용하였으며, discriminator net은 maxout activation을 사용하였다. Dicriminator 학습 과정에서는 dropout이 적용되었다.

해당 모델을 통해 생성된 샘플이 기존의 방식보다 뛰어나다고 할 수는 없지만, 경쟁력이 있으며, adversarial framework의 가능성을 시사한다.
Advantages and disadvantages
Disadvantages
- $ p_g(x) $가 명시적으로 표현 불가능하다.
- 학습 시 D와 G가 잘 synchronized되어야 한다. - 특히 D를 업데이트 하지 않은채로 G를 너무 많이 학습시켜선 안된다. "the Helvetica scenario"가 발생할 수 있다. (G가 여러 개의 z를 같은 값의 x에 할당하게 된다.)
Advantages
- Markov chain이 필요 없이 역전파로만 training이 가능하다.
- 학습 시 inference가 필요하지 않다.
- 모델에 다양한 함수를 적용할 수 있다.
- Generator network가 실제 데이터셋이 아니라, discriminator를 거친 gradient를 통해 업데이트 되므로 입력 component들은 generator의 파라미터에 직접적으로 복사되지 않는다.
- sharp, 더 나아가 degenerate한 분포를 나타낼 수 있다. - Markov chain에 기반한 모델은 mode 간 혼합이 가능하게끔 흐릿한 분포로 나타난다.
'방학 세션 > CV' 카테고리의 다른 글
| [6주차 / 진유석 / 논문리뷰] Generative Adversarial Nets (0) | 2023.02.22 |
|---|---|
| [6주차 / 신인섭 / 논문리뷰] Generative Adversarial Nets (0) | 2023.02.21 |
| [6주차 / 천원준 / 논문리뷰] Generative Adversarial Nets (0) | 2023.02.21 |
| [6주차 / 문성빈 / 논문리뷰] Generative Adversarial Imitation Learning (0) | 2023.02.21 |
| [6주차 / 논문리뷰 / 윤지현] Generative Adversarial Nets (0) | 2023.02.21 |





댓글 영역