고정 헤더 영역
상세 컨텐츠
본문 제목
[5주차 / 진유석 / 논문리뷰] AN IMAGE IS WORTH 16X16 WORDS: TRANSFOREMR FOR IMAGE RECOGNITION AT SCALE
본문
https://blog.naver.com/andrew9909에도 동일한 글을 작성하고 있습니다.
0. 들어가며
Transformer는 기본적으로 NLP 분야에서 나온 개념입니다. 기계 번역에 처음 사용되었고, CV 분야보다 음성 인식 / 음성 합성 등의 음성신호처리 분야에 Transformer 구조가 먼저 적용된 이유 역시 음성 데이터가 자연어처럼 시퀀스(순서를 가지는) 데이터이기 때문에 후에 서술할 positional encoding 등의 적용이 비슷하게 이루어지기 때문입니다. 그래서 Vision Transformer라는 이름을 처음 들었을 때 아주 신기했는데요, 컴퓨터 비전에서 제한적으로만 사용되었던 Transformer의 구조를 거의 완벽히 따라 좋은 성능을 냈다는 점에서 큰 contribution이 있다고 생각합니다.
1. seq2seq 모델의 한계
Transformer라는 모델이 2017년에 나오기 이전에는 seq2seq라는 모델이 자주 쓰였습니다. seq2seq, 그리고 음성 인식에 적용된 LAS(Listen, Attend and Spell) 논문에 대한 설명은 아래 글을 참고해 주세요.
https://blog.naver.com/andrew9909/222798842005
https://blog.naver.com/andrew9909/222807489479
본 포스팅에서는 seq2seq 모델의 구조 자체에 대한 이야기는 하지 않도록 하겠습니다. 한계점에 대해 간략하게만 설명하자면, 제가 생각하는 문제점들은 다음과 같습니다.
1) 고정된 길이의 context vector를 사용하니 문장의 길이가 길어질수록 정보 손실이 발생한다.
사실 이게 가장 큰 문제점인데요, 가령 '나는 고등학생이다. 매일 아침 ___에 간다'. 라는 학습 데이터가 있을 때 빈칸에 고등학교, 학교 등을 넣는 것은 어렵지 않습니다.
그런데 '나는 고등학생이고, 부모님과 형 한 명이 있다. 부모님과 형은 회사원이라 매일 회사에 가고, 나는 매일 __에 간다.' 라는 문장이 있으면, 앞 문장보다는 조금 더 답을 내기가 어려울 것입니다. seq2seq 모델에서는 인코더 RNN에 단어 토큰을 하나하나 넣고, 맨 마지막 토큰이 들어간 후 나온 은닉 상태(hidden state)를 가지고 디코더 RNN에서 출력을 진행하는데요, 따라서 앞 부분에 정보는 많이 소실될 수밖에 없습니다. 맨 마지막의 은닉 상태를 입력 문장의 '문맥을 담고 있는 벡터'라고 해서 context vector라고 하는데, 이 context vector가 고정된 길이이다 보니 정보 손실이 발생하는 것입니다. 이 문제점을 해결하고자 그냥 RNN(바닐라 RNN이라고 합니다) 대신 이전 토큰을 조금 더 잘 기억할 수 있는 LSTM을 사용하기는 하지만, 어쨌든 고정된 길이의 context vector를 내보내니 정보 손실이 발생하는 것은 마찬가지입니다.
2) 하나 하나 넣다 보니 병렬 처리가 안 된다.
RNN의 구조는 하나를 넣으면 하나가 나오고, 그걸 또 넣고 하는 방식입니다. 애초에 구조가 이렇다 보니 이전 출력이 나와야만 그걸 지금 입력으로 넣어줄 수 있습니다. 그래서 시간이 오래 걸립니다. 딥러닝 특성상 바로바로 수정할 수 있는 것이 아니라 하루쯤 돌려보고 엥 좀 이상한데? 해야 하기 때문에 학습 시간의 단축은 모델 성능과 연구자의 정신 건강에 모두 중요한 문제입니다. 암튼 이 부분에서 RNN은 절대 강점을 가질 수가 없다고 생각합니다.
2. Transformer
이런 문제를 한 번에 없애버린 게 바로 Transformer 논문입니다. 요즘 유행하는 ChatGPT나 BERT같은 유명한 모델들은 전부 이 Transformer 구조를 기반으로 만들어졌습니다.

Transformer의 전체 구조는 위 그림과 같은데요, 이 중에서 Self-attention과 Positional Encoding에 대해 이야기해보겠습니다.
1) self-attention
이 self attention 덕분에 앞서 언급한 문제 두 가지가 모두 해결되었습니다. 앞 부분에 정보를 잃을 일도 없고, 차례대로 입력 데이터가 들어가느라 시간이 오래 걸리는 일도 없습니다. 그 이유는 한 번에 모든 것을 넣어 모든 것을 참조하기 때문입니다.

위 그림에서 '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤했기 때문이다' 라는 문장에서 '그것'이 동물을 의미하는 것은 사람들은 잘 알지만, 컴퓨터는 바로 알 수가 없습니다. 컴퓨터에게는 animal이든 street이든 it이든, 같은 차원으로 임베딩된 벡터이기 때문입니다. self attention을 통해 컴퓨터도 it이 animal을 의미한다는 것을 알 수 있습니다. 그리고 앞서 언급했듯 저 문장들은 한 번에 들어갑니다. 기존 RNN이 The를 넣고 animal을 넣고.... tired가 들어가서 나온 결과를 디코더에 넣는 것과는 다릅니다.
self attention은 Q(Query), K(Key), V(Value) 3개의 행렬을 통해 진행되는데요, 그 과정에 대해 알아보겠습니다.
① 입력 데이터
먼저 입력 데이터는 (토큰 개수 x 임베딩 차원)으로 이루어집니다. 아래 그림의 경우 토큰은 I, am, a, student 4개이고, 임베딩 차원도 4입니다. 만약 임베딩 차원이 512였다면 (4 x 4) 행렬이 아니라 (4 x 512) 행렬이 되었을 것입니다.

② 입력 데이터를 통해 Q, K, V 만들기
(n_token, embedding_dim) 차원의 입력 행렬을 가중치 행렬 W^Q, W^K, W^V와 내적해 Q, K, V 벡터를 만듭니다. 내적을 해야 하기 때문에 가중치 행렬 W는 (embedding_dim, w_dim) 차원을 가지게 되고, 내적을 하니 중간이 사라져 Q, K, V는 각각 (n_token, w_dim) 차원으로 구성됩니다. 위 그림의 경우 w_dim은 2입니다.
③ Q, K^T의 내적 수행하기
Query는 질문, Key는 답변입니다. 나랑 유사한 사람 누구?(Q) 나!(K) 이를 표현하기 위해 Q와 K^T를 내적합니다. (n_token, w_dim) · (w_dim, n_token)의 내적 결과는 (n_token, n_token)의 정사각행렬입니다. i행 j열의 숫자는 i번째 토큰이 j번째 토큰과 얼마나 관련되어 있는지를 나타냅니다. 예를 들어 1행 4열의 원소는 'I'라는 토큰이 '너 나랑 얼마나 비슷해?' 라고 'student' 토큰에게 물어본 결과를 나타내고 있습니다.
생각해보면 '모든 것'을 참조한다고 했으니 한 토큰이 모든 토큰을 참조해야 하고(1, n_token), 그런 토큰이 n_token개만큼 있으니 (n_token, n_token) 모양의 행렬이 생성되는 것은 당연합니다. 또, 대각원소들은 각자 자신과의 유사도를 나타내니 값이 당연히 높을 것입니다.

④ scaling & softmax
각 원소들을 쿼리, 키 차원에 루트를 씌운 값으로 나누어줍니다. 논문에서는 그 이유를 'We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients'라고 했는데요, 뭔가 엄청난 수학적 의미보다는 많은 딥러닝 논문들이 그렇듯 experimental result가 아닐까 싶습니다. 좀 더 극단적으로 치우치게 softmax 이후의 값을 얻고 싶을 때 각 값에 상수를 곱하기도 하는데, 그 반대 개념이라고 이해하면 될 것 같습니다.
이후 행들끼리 softmax를 거치고, 각 행의 합이 1로 변하게 됩니다. 이제 각 원소들은 0과 1 사이의 값을 가지게 되었는데, 이를 가중치라고 하기도 하고 에너지라고 하기도 하고 어텐션 스코어라 하기도 하고, 아무튼 유사한 정도를 0과 1 사이의 숫자로 표현하게 됩니다.
⑤ scaling된 행렬과 V를 내적해 주기

(n_token, n_token)의 행렬을 (n_token, w_dim)의 행렬과 내적해 (n_token, w_dim)의 행렬을 얻고, 이걸 Attention value matrix라고 합니다. 위 그림에서 I라는 토큰은 I, student와 0.4 / am, a와 0.1만큼 유사하다고 나왔으니 value에서 I, student는 40퍼센트씩 참고하고, am, a는 10퍼센트씩 참고하게 됩니다. 그래서 w_dim 차원의 첫 번째 행이 구성되는 것입니다. 이를 각 토큰에 대해 반복해 (n_token, w_dim) 만큼의 차원이 생깁니다. 이 과정을 요약하면 아래 식과 같습니다.

* Multi-head Self Attention
Multi-head Self Attentinon은 이름 그대로 self attention 과정을 한 번에 하지 않고 여러 개로 나누어서 진행하는 것입니다. 즉, '여러 개'의 개수를 8개라고 하고, w_dim이 512라고 하면, 위 attention 과정을 8개의 가중치 행렬을 따로 학습시켜 가면서 8번 진행합니다. 그럼 좋기는 한데 그냥 attention 계산량이 8배가 되기 때문에, w_dim을 512//8 = 64로 차원을 축소해 주고, 이후에 concat을 통해 64 * 8 = 512가 그대로 복원될 수 있도록 합니다. 한 번에 하나 여러 개로 나누어서 하나 계산량도 비슷하고 결과 차원도 똑같은데 왜 그렇게 하나? 생각을 해 봤는데 아무래도 요리보고 조리보고 할 수 있다가 가장 큰 이유인 것 같습니다.

2) Positional Encoding
'한 번에 넣는다'가 Transformer의 가장 큰 특징이고 장점이라고 했습니다. 근데 여기서 딱 하나 단점이 생기는데요, 한 번에 넣었기 때문에 순서 정보가 사라진다는 것입니다. 기존의 경우 하나 넣고 또 하나 넣고 하는 식의 구조이기 때문에 속도가 느리긴 하지만 그 자체로 순서 정보가 생기지만, transformer에서는 그렇지 못합니다. 이를 해결하는 것이 '위치 정보를 더해주는 인코딩', positional encoding인데요, 수식은 아래와 같습니다. (논문에서는 d_model = 512이므로, i ∈ [0, 255])

방법은 주기가 다른 삼각함수의 값들로 위치 정보를 삼는 것입니다. 아래 그림은 짝수 차원의 사인함수를 나타내고 있습니다.

아래로 내려갈수록 주기가 길어지는 sin 함수에서 각 값들을 뽑습니다. 0번과 6번의 위치가 달라서 각 삼각함수의 값들도 다른 것을 알 수 있습니다. 이를 통해 위치 정보를 나타내는 것입니다. 아래 그림은 제가 positional encoding을 설명할 때 가장 좋아하는 그림인데요, 한 번에 돌리는 칸 수가 다른 톱니바퀴들을 주고, 이 위치에서 톱니바퀴가 얼마나 돌려졌느냐에 따라 위치 정보를 얻는 방식입니다.

3. Vision Transformer
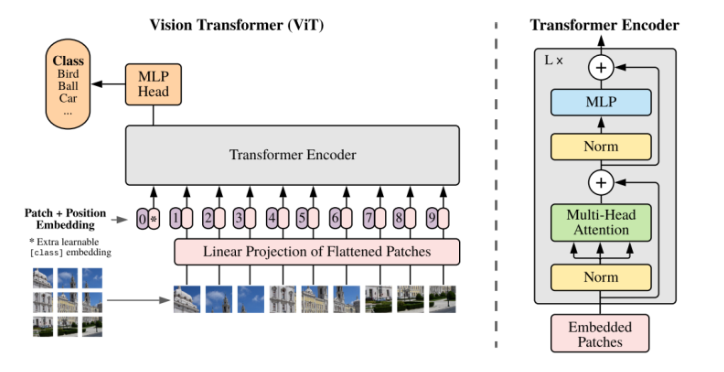
이를 그대로 비전에 적용시킨 것이 Vision Transformer입니다. Layernorm과 residual connection의 위치가 살짝 다르고, MLP에서 활성화 함수로 GELU를 사용했다는 점이 다릅니다.

이미지 데이터를 어떻게 시퀀스 데이터처럼 다루는가? transformer 구조를 적용시키는 방법은 이미지를 쪼개 늘어뜨려서 시퀀스 데이터처럼 만들고, 거기에 위치 정보를 더해 주는 것입니다. 이 쪼갠 하나하나를 '패치'라고 합니다.
본래 이미지는 채널 x 가로 x 세로로 구성됩니다. (C, W, H) 이를 N개의 패치로 쪼갭니다. 위 식에서 P는 패치의 크기를 의미합니다. 이를 transformer 입력 구조에 맞게 flatten해서 (P^2C) 길이의 벡터를 n개 만듭니다.
이제 N개의 embedding matrix E를 통해 D차원으로 embedding해 줍니다. D차원이 N개니 (N x D) 만큼이 있습니다. ViT는 image classification을 위한 모델이므로, 여기서 클래스 토큰을 맨 첫 번째에 하나 추가해 줍니다. 이후 positional encoding을 하여 위치 정보를 추가해준 후 입력 데이터로 사용합니다. 인코더를 거쳐 나온 output 중에 class token만 classification에 사용합니다.
4. 실험 결과
큰 데이터셋에 대해 pretrain한 후 작은 dataset으로 fine-tuning을 진행합니다. 그 이유는 inductive bias라는 것 때문에 더 많은 데이터가 필요하기 때문이라고 합니다. 결과는 잘 나왔습니다.


Positional Encoding도 잘 된 모습입니다. 밝을수록 cosine similarity가 높은 것인데요, 중앙에 있는 패치는 중앙이 높게, 가장자리에 있는 패치는 가장자리가 높게 잘 나왔습니다.

원논문)
https://arxiv.org/abs/2010.11929
참고자료)
https://gaussian37.github.io/dl-concept-vit/
https://blog.naver.com/hoon_life/223012479648





댓글 영역