고정 헤더 영역
상세 컨텐츠
본문 제목
[논문 리뷰 스터디] HOTR: End-to-End Human-Object Interaction Detection with Transformers
본문
작성자 : 17기 임청수
0. Abstract
HOI detection : 이미지 내에서 set of interactions를 탐지하는 task를 의미한다.
→ 쉽게 말해 사람과 물체간의 상호작용을 탐지하는 역할을 한다.
화면에 등장하는 사람과 물체간의 상호작용을 human, object, interaction 형태로 bounding box와 classfication을 활용하여 표현한다.

- human, objects를 localization → 사람과 물체를 localize 후 분류
- interaction label로 분류 하는 과정을 거침 → interaction association을 찾음
기존에는 객체를 탐지하고 각각 pair를 만든 후 interaction을 파악하는 방식으로 2단계에 나누어 간접적으로 수행했다.
HOTR은 human, object, interaction triplets을 이미지에서 한번에 예측해낸다.
이를 통해 후처리 과정을 제거하여 소요 시간을 상당히 줄였다. inference time을 1ms 미만으로 축소시키면서 SOTA를 달성했다.
1. Introduction
이전에는 HOI detection시 2단계로 나뉘어 진행되었다. 객체 탐지를 한 후 두 쌍을 연결하여 후처리 단계를 수행했다. sequential HOI detector는 후처리 과정에서 NN를 사용했기 때문에 시간과 계산비용이 상당히 컸다.
따라서 inference시간을 줄이기 위해 parallel HOI detector가 제안되었다. 여기서는 후처리단계에서 interaction box나 union box를 활용했다. 이렇게 localize된 box들은 triplet을 구성했다. 기존 NN은 distance or IoU로 대체되었다.
하지만 여전히 1) 후처리 단계는 필요하며(임계값 설정, 중복 예측 제거 등) 2) interaction자체에 높은 의존성에 대한 연구가 필요하다.
2. Related Work
1) Sequential HOI detector
- interactNet - detecting and recognizing human object interactions
→ 하나의 이미지에 사람과 물건이 있을 때 어떠한 interaction을 취할지, 예측할 수 있는지, 한 이미지 내에 한 사람이 여러 물건과 Interaction한다면 그 물건을 어떻게 찾을 수 있는지를 지적하고 해결방안 제시
→ 한 이미지 내의 모든 물체를 탐지하고 모든 pair에 대해 sequential한 NN을 활용하여 interaction을 추론하는 방법
→ interactNet을 통해 triplet마다 스코어를 구하고 스코어가 높은 것만 이미지에 bounding box 표현
- 한계
pairwise Neural network를 사용하면서 시간, 계산비용 증가
- iCAN
→ attention map을 이용하여 interaction 탐지 효과를 높였다.
물체의 apperance가 이미지에 어떤 영역과 관련이 있을지를 attention map을 통해 해결한다.
다시 말해 외형적 특징을 함께 고려하여 동작을 인지하도록 하는 알고리즘을 적용했다.
- 한계
직관적인 파이프라인과 좋은 성능을 갖지만 object detection이후 NN 과정의 시간과 비용소요 단점을 지닌다.
2) Parallel HOI Detector
→ 기존 2스테이지를 1스테이지 방식으로 변환한다. NN대신 interaction box나 union box를 활용했다. 따라서 성능을 유지하면서 inference time을 효과적으로 줄였다.
- PPDM
직적접으로 interaction에 대해 interaction points or union boxes로 localize한다.
NN를 통한 interaction prediction은 distance or IoU에 의한 simple heuristic based matching으로 대체한다.
하지만 hand crafted 후처리 단계가 여전히 존재한다.
Non-Maximum Suppression은 object detector가 예측한 bounding box 중에서 정확한 bounding box를 선택하도록 하는 기법
threshold, 내림차순 정렬, IoU 계산…
- threshold를 설정해야 하고 2) 각 object pair를 localized interaction과 매칭시키는데도 많은 시간이 든다.
2.2 object detection with transformer
따라서 이러한 후처리 단계를 대체하기 위해 transformer의 구조를 활용한 HOTR이 등장하게 되었다.
HOI detector는 object detection과 관련이 깊기 때문에 HOTR 또한 object detection에 transformer 구조를 적용한 DETR 모델과 유사한 구조를 가지고 있다.
→ (End-to-End Object Detection with Transformers (DETR))
다시 말해 feature extraction, encoder, decoder, output까지의 archtecture는 유사하다.

다만 task의 목적이 다르기 때문에 DETR은 N개의 object query를 고정하고 decoder 결과값에 대해 N bounding box classifier를 활용한 N prediction을 수행하는 반면,
HOI detector는 prediction head에서 사람, 물체, 상호작용 세 가지에 대한 triplet을 output으로 한다는 차이점이 있다.
HOTR의 loss는 triplet을 prediction한 값과 ground truth값을 최적으로 매칭하도록 설정한다.
3. Method
3.1 detection as set prediction
HOI detection은 human, object, interaction을 동시에 다루기 때문에 multi label classification of the interaction type이라고 이해할 수 있다.
따라서 MLP의 head를 수정하여 모든 positional embedding마다 human box, object box, action으로 분류 한다.
문제는 동일한 객체가 동시에 여러 개의 interaction을 수행할 수 있다는 것이다. 따라서 localization이 중복되게 prediction이 되어야 한다.
ex 1)의자에 앉아서 2)컴퓨터 게임을 한다.
이러한 문제를 두 개의 decoder를 사용하면서 해결했다.
3.2 HOTR archtecture
HOTR은 transformer와 마찬가지로 encoder와 decoder의 구조를 가지고 있다. 각각 shared encoder와 2개의 parallel docoder를 사용한다.
<흐름 정리>
- 이미지를 CNN backbone에 의해 feature map 추출
- feature map은 positional embedding을 거쳐 share encoder에 입력
- share encoder를 통해 전반적인 context이 추출됨
- encoder의 결과값은 각각 instance decoder와 interaction decoder에 들어감
- 각각의 decoder에서 representation이 학습되어 xx representation형태가 됨
- 이렇게 출력된 두 representation은 FFN(feed forward N)을 거친 HO pointer라는 개념을 활용하여 매칭

위 figure2는 전반적인 Architecture를 담고 있다.
여기서 두 parallel decoder의 Output인 representation을 결합할 때 HO pointer를 이용하여 최종적으로 Triplet set을 구성하게 된다.

자세히 설명하자면, 우선 interaction representation에 3가지 FFN을 적용하여 3개의 output(human pointer, object pointer, interaction type)을 얻는다.
그리고 추출된 pointer는 모든 instance representation과 유사도를 비교하여 가장 높은 유사도를 가지면 매칭시킨 후 localization을 수행한다.
이렇게 두 개의 decoder로 나눈 후 매칭시키는 방법을 사용하면서 얻을 수 있는 이점은 다음과 같다.
같은 이미지에는 여러 개의 interaction이 존재할 수 있다. 위 사진에서 사람은 빵을 먹는 행위와 의자에 앉는 행위를 동시에 하면서 2가지 interaction을 보인다.
하지만 pointer를 활용하여 매칭하면서 H pointer는 같은 사람의 bounding box를 매칭하고 bread와 chair는 다른 bounding box를 매칭하게 되고 한번에 여러 개의 interaction을 표현할 수 있게 된다.
이 방법을 통해 동일한 대상에 대해 중복학습을 할 필요가 없어졌고 기존 Parallel HO detector에 비해서 Inference 타임을 줄일 수 있었다.
기존에는 distance나 IoU로 triplet을 매칭했다면 HO pointer에는 미리 정해진 N개의 instance에 대해서 k개의 interaction을 매칭하기 때문이다. 실제로 NMS 등의 post processing 단계를 없앰으로서 기존 방법 대비 inference time을 4~8 m/s 단축했다고 설명하고 있다.
Set prediction

유사도를 계산하여 가장 유사도가 높은 instance presentation을 pointer와 매칭한다.

instance representation 값을 FFN에 입력하여 final HOI prediction을 수행하고 결과값으로 set of k triplet을 얻는다.
3.3 Training HOTR
Transformer 구조를 가진 모델을 설계하면서 set prediction을 구현했지만 실제 데이터셋을 학습하기에는 문제가 있다. 하나의 이미지 안에 interaction 개수가 정해져 있지 않다는 것이다. 이미지 내의 interaction 수는 이미지마다 다를 수 밖에 없다. 이러한 문제를 해결하기 위해 hungarian 알고리즘을 활용했다.
헝가리안 알고리즘은 이분 그래프에서 최적의 매칭을 찾는 알고리즘이다.
논문에서는 먼저 하나의 이미지에 있을 수 있는 최대 query 수를 N개로 정하여 max length값으로 설정한다. 여기서 각 N개를 매칭시켜 학습해야 하기 떄문에 ground truth와 training output label을 매칭해주어야 한다.

좌측 상단의 수식은 ground truth값과 학습의 결과값을 매칭한 것이다.
매칭된 모든 pair에 대해 Hungarian loss를 matching cost function으로 정의한다.
final set prediction loss for HOTR은 HOI Triplet의 Localization loss와 action classification loss를 합산하여 계산한다.
No Interaction with HOTR
목적이 object detection인 DETR은 softmax output에서 no-object class 확률값이 다른 class값보다 큰 경우로 정의한다.
하지만 목적이 HOI detection인 HOTR은 각각의 interaction들이 binary형태로 나타나는 multi label classification이다.
따라서 모든 class들은 상호작용이 있으면 1, 없으면 0으로 분류되고 threshold(=low interaction score = suppress )이면 no interaction class로 define된다.
4. Experiments

두 데이터셋에 대해 실험을 진행하여 성능 개선을 확인했다.
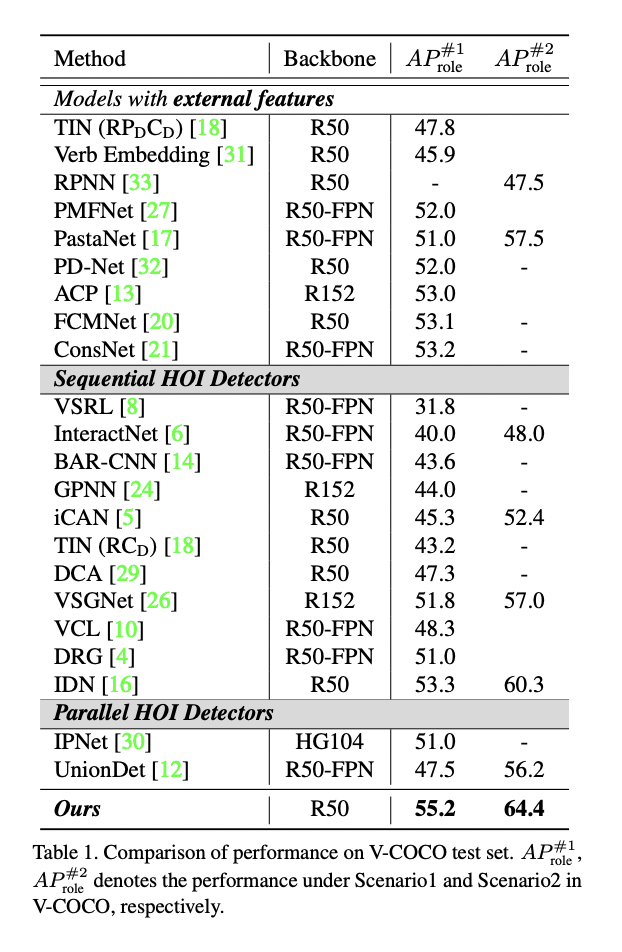
V-COCO는 Sequential prediction보다 1.9에서 4.1AP 정도 성능 향상을 보였고, Parallel HOI detector에 대해서 7.2에서 8.2AP 정도 성능향상을 보였다.

HICO-DET도 마찬가지로 HOTR이 대체적으로 더 좋은 결과를 보여주고 있다.

HO pointer를 사용하면서 39.5에서 55.2로 17.7AP 정도 성능향상을 보였다. 또한 Interactiveness Supression을 통해 각 클래스들을 독립적으로 multi label banary classification을 적용하면서 3AP 정도의 성능향상을 보여주었다.
5. Conclusion
→ transformer를 HOI detection에 적용한 모델이다.
→ 기존 모델과 달리 NN과 NMS 등 후처리 단계를 제거하면서 inference time을 줄이고 성능을 향상시켰다.
→ 두 개의 decoder를 사용하는 모델을 제안했고 유사도 기반으로 합치는 HO pointer를 제안했다.
→ 제안한 모델로 sota를 달성했고 기존 모델에 비해 Inference time이 5m/s 정도 감소하는 효과를 보였다.
6. Reference
paper : https://arxiv.org/abs/2104.13682
blog : DETR - https://dhk1349.tistory.com/19
youtube : https://www.youtube.com/watch?v=pkbLrLSDQ9Q

'심화 스터디 > 논문 리뷰 스터디' 카테고리의 다른 글
| [논문 리뷰 스터디] 부트스트랩을 활용한 이상원인 변수의 탐지기법_실제 적용 (0) | 2023.05.31 |
|---|---|
| [논문 리뷰 스터디] Denoising Diffusion Probabilistic Models (0) | 2023.05.31 |
| [논문 리뷰 스터디] U-Net : Convolutional Networks for Biomedical Image Segmentation (1) | 2023.05.31 |
| [논문 리뷰 스터디] FDA: Fourier Domain Adaptation for Semantic Segmentation (0) | 2023.05.31 |
| [논문 리뷰 스터디] SECOND: Sparsely Embedded Convolutional Detection (0) | 2023.05.30 |





댓글 영역