고정 헤더 영역
상세 컨텐츠
본문 제목
[논문 리뷰 스터디] U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
본문
작성자: 16기 임채명

Abstract
U GAT IT의 의의
- source와 target 도메인 간 차이를 보다 잘 반영하는 new attention module을 제안함
- shape와 texture를 보다 유연하게 조정할 수 있도록 새로운 normalization function을 도입함: AdaLIN (Adaptive Layer-Instance Normalization) function
Introduction
img2img translation은 한 도메인에서 다른 도메인에 이미지를 mapping하는 function을 학습하는 것을 목표로 하며, image inpainting, super resolution, colorization, style transfer 등에 다양하게 쓰인다.
기존 연구들은 도메인 간 shape와 texture의 변화량에 따라 성능의 차가 컸다. 예를 들어 photo2portrait 같이 도메인 간 차이가 적을 때는 잘 작동하지만 selfie2anime처럼 larger shape change가 있을 때에는 성능이 좋지 않았음
이를 해결하기 위해 이미지 데이터 분포의 복잡도를 줄여주는 전처리 기법들이 사용되었음. 추가적으로 DRIT와 같은 기법들은 모양을 보존하는 과제(horse2zebra)와 모양을 바꾸는 과제(cat2dog) 모두에서 고정된 모델 구조와 하이퍼파라미터로도 좋은 성과를 보여주었다. 다만, 각 과제에 대해 모델 구조나 하이퍼파라미터를 수정해줘야 함.
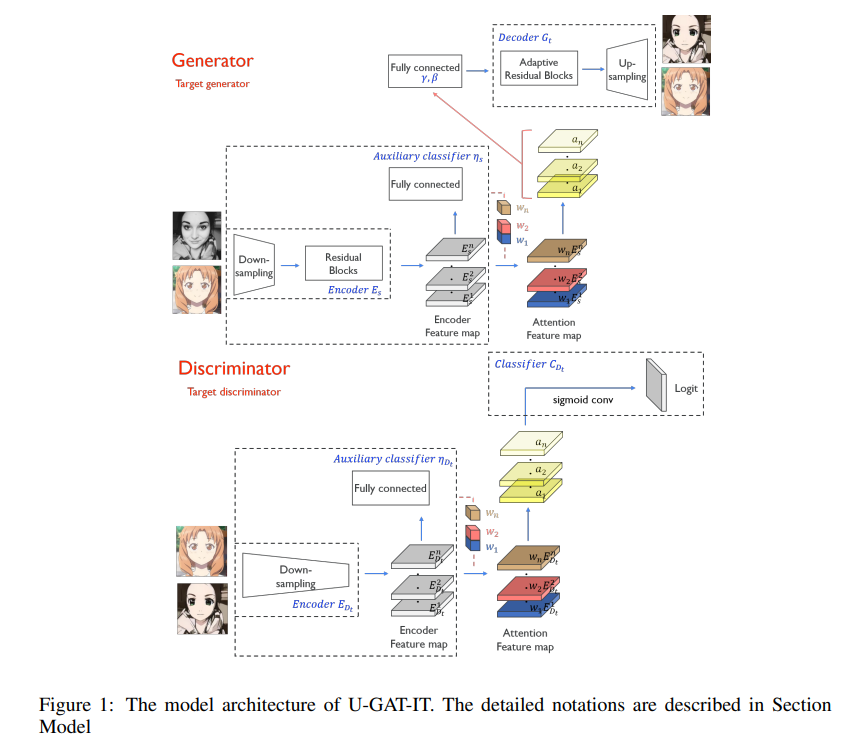
본 연구에서는 unsupervised img2img translation을 위해 new attention module과 new normalization function을 제안한다. 새로운 모델은 auxiliary classifier(보조 classifier)를 사용하여 얻은 attention map을 바탕으로 source와 target 도메인 사이의 차이를 구분한다. 해당 attention maps는 중요한 area에 집중하기 위해 generator와 discriminator에 더해진다.
- generator에 더해지는 attention map: 두 도메인 간의 차이에 집중
- discriminator에 더해지는 attention map: 진짜 이미지와 생성된 fake 이미지 간의 차이에 집중
이에 더해 datasets with different amounts of change in shape and texture에 적합한 새로운 normalization function을 제안한다 -> Adaptive LayerInstance Normalization (AdaLIN)
해당 function은 Instance normalization (IN)와 Layer Normalization (LN)의 비율을 데이터에 맞게 적절하게 적용할 수 있도록 하며, 파라미터는 training 과정에서 학습된다.
본 연구는 모델 구조나 하이퍼파라미터 조정없이 larger shape change에도 적용가능하다.
Unsupervised Generative Attentional Networks With Adaptive Layer-Instance Normalization
해당 모델의 목표는 unpaired sample만을 이용하여 source 도메인 $X_{s}$의 이미지를 target 도메인 $X_{t}$로 mapping하는 function $G_{s\rightarrow t}$를 학습하는 것이다.
해당 모델은 두개의 generator $G_{s\rightarrow t}$, $G_{t\rightarrow s}$와 두 개의 discriminator $D_{s}$, $D_{t}$로 구성되며 generator와 discriminator에 모두 attention module을 추가한다.
앞서 말했듯, generator에 더해지는 attention의 경우, 도메인 간 차이에 집중하고, discriminator에 더해지는 attention의 경우, realistic한 이미지를 구현하는 데에 중요한지역에 집중한다.
Generator
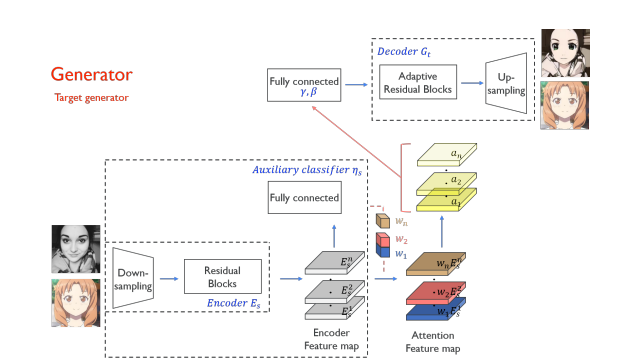
$x\in \left\{ X_{s}, X_{t}\right\}$: source와 target 도메인에서 온 sample
$G_{s\rightarrow t}$는 encoder $E_{s}$, decoder $G_{t}$, auxiliary classifier $\eta_{s}$ 3개로 구성됨
이때 $\eta_{s}(x)$: $x$가 $X_{s}$에서 왔을 확률
- Encoder 설명
$E^{k}_{s}(x)$: encoder의 kth activation map
$E^{k_{ij}}_{s}(x)$: encoder의 kth activation map의 (i, j)에서의 값
- auxiliary classifier 설명(CAM 모델에서 영감 받음)
CAM(Class Activation Mapping): CNN에서 마지막 FCN을 제거하고 Global Average Pooling을 적용하는 방법이다. CNN의 마지막에 붙은 classifier가 class score를 낼 때, weight 값을 보면 어떤 feature map이 그 score에 가장 많이 기여했는가를 알 수 있다. 그 weight를 feature map과 곱하면 attention map이 된다.
보조 classifier는 source 도메인의 kth feature map의 weight $w^{k}_{s}$를 학습하기위해 훈련된다.
이에 global average pooling과 global max pooling을 사용
수식으로 표현하면 $\eta_{s}(x) = \sigma(\sum_{k}w^{k}_{s}\sum_{ij}E^{k_{ij}}_{s}(x))$
또한 출력값의 측면에서 이를 바라보면, $w^{k}_{s}$를 얻음으로써 우리는 domain specific한 attention feature map $a_{s}(x)$를 계산할 수 있다.
$a_{s}(x) = w_{s}*E_{s}(x) = \left\{w^{k}_{s}*E^{k}_{s}(x)|1\leq k \leq n\right\}$
여기서 n은 encoded feature map의 개수
$x$가 $X_{s}$에서 왔을 확률 = x가 $X_{s}$에 얼마나 기여를 했는가 = attention map는 Encoder가 추출한 feature map에 weight를 곱하여 알 수 있음
- decoder 설명
Encoder가 추출한 feature map이 auxiliary classifier가 만들어 낸 attention과 곱해져서 decoder의 input이 된다.
즉 $G_{s\rightarrow t}$는 $G_{t}(a_{s}(x))$와 같게 된다.
AdaLIN은 각 residual block마다 적용되는데, 파라미터 $\gamma, \beta$는 attention map의 fc layer에서 계산된다.

$\mu_{I}, \mu_{L}, \sigma_{I}, \sigma_{L}$: 각각 channel-wise, layer-wise 평균과 표준편차
$\tau$: learning rate
$\Delta \rho$: optimizer에 의해 결정되는 gradient
$\rho$는 [0, 1]의 범위를 가지도록 함. Generator는 instance normalization이 적합한 과제에서는 $\rho$값을 1에 가깝게 조정하고 layer normalization이 적합한 과제에서는 $\rho$값을 0에 가깝게 조정한다.
decoder의 residual blocks에는 $\rho$을 1로 up-sampling blocks에서는 $\rho$을 0으로 초기화
결국 Instance normalization (IN)와 Layer Normalization (LN)의 비율을 데이터에 맞게 적절하게 적용!
AdaLIN 도입 이유: 최적의 방법은 Whitening and Coloring Transform(WCT)를 적용하는 것이지만 computational cost가 너무 크다. AdaIN은 WCT보다 빠르지만 feature channels간의 uncorrelation을 가정하기 때문에 변환된 features는 실제 content보다 더 많은 패턴을 포함하고 있다. 반대로, LN은 channels간의 uncorrelation을 가정하지는 않지만, LN은 Feature maps에 대해서만 global statistics를 고려하기 때문에 original 도메인의 content 구조를 잘 유지하지 못한다.
AdaLIN은 AdaIN과 LN의 장점을 결합시켰다. -> keeping or changing the content information!
Discriminator

$x \in \left\{X_{t}, G_{s\rightarrow t}(X_{s}) \right\}$를 target 도메인 sample과 source 도메인에서 온 translated sample이라고 하자.
판별자 $D_{t}$는 인코더 $E_{D_{t}}$, classifier $C_{D_{t}}$, 보조 classifier $\eta_{D_{t}}$로 구성
판별자와 보조 classifier 둘 다 x가 $X_{t}$에서 왔는지 $G_{s\rightarrow t}(X_{s})$에서 왔는지 구분하도록 학습된다.
생성자와 마찬가지로, Encoder가 추출한 feature map이 auxiliary classifier의 weight과 곱해져서 classifier $C_{D_{t}}$의 input이 된다. (즉, $D_{t}$는 $C_{D_{t}}(a_{D_{t}}(x))$)
Loss Function
손실함수는 총 네가지 부분으로 구성된다. 또한 안정적인 학습을 위해 vanilla GAN loss를 쓰는 게 아니라 Least Squares GAN loss를 쓴다.
(1) Adversarial Loss: traslated images가 target image distribution와 유사한 distribution을 가지도록 함
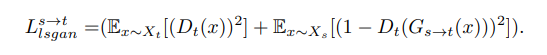
(2) Cycle Loss: mode collapse 문제를 방지하기 위해 x와 $G_{t\rightarrow s}(G_{s\rightarrow t}(x))$가 유사해지도록 학습

*mode collapse 문제: generator가 고른 분포를 가진 (다양한) fake data를 만들어 내지 못하고 비슷한 data만 계속 생성하는 붕괴된 상태
(3) Identity Loss: input과 output 이미지 간의 색상 분포가 비슷하도록 학습(x와 $G_{s\rightarrow t}(x)$과 유사하도록)

(4) CAM loss: 보조 classifier $\eta_{s}}$와 $\eta_{D_{t}}$에 대한 loss

Full objective: 본 연구에서는 $\lambda_{1}$ = 1, $\lambda_{2}$ = 10, $\lambda_{3}$ = 10, $\lambda_{4}$ = 1000.
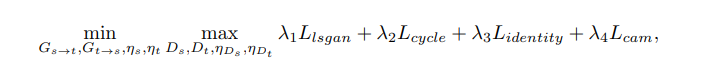
Experiments

(b)를 보면, attention feature map이 생성자가 눈 혹은 입처럼 target 도메인과 sorce 도메인 간의 차이가 큰 특성들을 잘 뽑아내는 것을 볼 수 있다. 또한 (c)와 (d)를 통해 discriminator에 더해지는 attention map은 진짜 이미지와 생성된 fake 이미지 간의 차이에 집중한다는 것을 확인할 수 있다. (e)와 (f)를 비교하였을 때, attention feature map를 추가하는 것이 더 좋은 결과를 낳는다는 것을 알 수 있다.

(b)를 보면 AdaLIN을 사용했을 때 transaltion이 가장 자연스러움

논문 원문: https://arxiv.org/pdf/1907.10830.pdf
공식 Tensorflow 코드: https://github.com/taki0112/UGATIT





댓글 영역