고정 헤더 영역
상세 컨텐츠
본문

본 포스팅은 Facebook에서 발간한 Forecasting at Scale 논문을 정리한 내용입니다.
작성자: 17기 김희준
1. introduction
본 논문에서는 시계열 모델 및 방법론에 대한 지식은 거의 없고, 생성 프로세스에 대한 지식만 있는 비전문가가 구성할 수 잇는 시계열 모델을 제시한다. 이 모델은 예측과 평가뿐만 아니라 성능이 낮아지는 시기까지 감지할 수 있다. 또한 과거 데이터를 사용하여 미래를 추정하고, 문제가 있는 예측을 식별하는 평가 시스템을 설명한다.

전체 과정을 analyst in the loop automated라고 부른다. 먼저 각 매개변수를 간단히 분석가가 매긴 후 시계열을 모델링한다. 그 후 이 모델에 대한 예측 성능을 평가한다. 만약 성능이 좋지 않거나 잠재적인 문제가 발생되면 이를 분석가에게 알려준다. 그런 다음 분석가는 피드백을 기반으로 모형을 조정하는 식이다.
2. Features of Business Time series
비즈니스 예측 문제는 매우 다양하지만 그 중 많은 문제에 공통적으로 드러나는 부분이 있다.
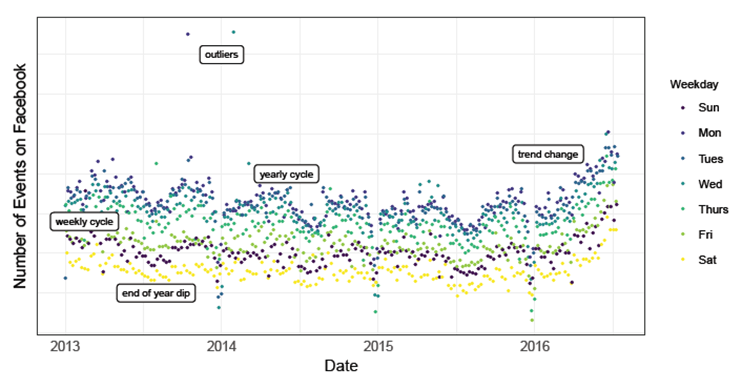
위 사진은 시계열 데이터의 계절성을 보여준다. 주간, 연간의 주기가 있고 연말 연초에 뚜렷한 하락이 있다. 또한 trend(추세)의 변화 역시도 명확하게 포착이 된다. 위 시계열 데이터가 앞서 언급한 완전 자동화 방법으로 예측을 하기에 무리가 있는 예시이다.

위 그림은 auto.arima, ets, 무작위 보행 모델 snive, tbats 네 가지를 사용하여 특정 시점의 데이터를 예측한 것이다. 네 가지 모델 모두 어려움을 겪고 있다. auto.arima는 예측이 시작되는 지점에서 추세가 급하게 변화하면 추세를 잘못 추정할 가능성이 크다. ets는 주간 계절성은 확실히 포착하지만, 장기 계절성은 놓치고 있는 모습이다.
물론 시계열 모델링에 대한 지식이 있다면, 파라미터 수정을 통해 이 같은 문제를 개선해나갈 수 있지만, 지식이 없는 분석가는 이러한 조정법을 알지 못한다. 자기회귀, ar, ma, 차분 등 알아야 할 개념이 매우 많기 때문이다.
3. The Prophet Forecasting Model
그래서 이 논문은 시계열 모델의 세부 사항을 모르더라도 직관적인 파라미터를 제공함으로써 이 문제를 개선해나가는 모델, prophet을 소개한다. prophet은 파이썬과 R에서 오픈소스로 사용이 가능하다. prophet 모델은 아래 세 가지 main 요소와 잔차로 구성된다.
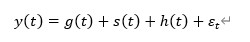
g(t)는 비주기적 변화를 나타내는 추세(trend) 함수, s(t)는 주기적인 변화, 즉 계절성을 나타내는 함수, h(t)는 holiday처럼 불규칙한 영향을 미치는 요소를 나타낸다. e_t는 정규분포를 따르는 잔차로, 세 가지 요소로는 설명되지 않는 에러를 표현하는 요소이다.
prophet은 여타 시계열 모델과는 달리, curve-fitting 방식으로 예측을 한다. 이로써 얻는 이점이 네 가지가 있다.
1. 유연성: 원하는 계절성을 자유롭게 가정할 수 있고, 추세에 대한 가정 역시 유연하게 반영할 수 있다.
2. ARIMA 모델과 달리 차분하거나 결측치를 보간할 필요도 없다. 또한 굳이 데이터의 시차가 일정하지 않더라도 이를 regularly spaced하게 만들 필요가 없다.
3. fitting 속도가 빠르기에 이것저것 파라미터 조정을 해가며 피드백을 하기에 수월하다.
4. 직관적인 파라미터 조정이 가능하다. 다시 말하면, 파라미터의 해석이 다른 모델들에 비해 쉬운 편이다.
3.1.1. Nolinear, Saturating Growth
성장 예측의 핵심요소는 인구가 얼마나 성장할 것이고, 이 성장이 얼마나 지속될 것인가이다. 특히 facebook에서의 성장 예측은 실제 자연 생태계의 인구 성장과 매우 유사하다. 자연 생태계에서는 한 개체가 최대로 존재할 수 있는 상한이 존재한다. 마찬가지로, facebook 사용자 역시도 상한이 존재한다. 이 때의 상한은 인터넷을 사용할 수 있는 전세계 인구 수일 것이다.
만약 예측하고자 하는 값의 상한, 하한이 있다면 로지스틱 함수로 수식을 나타낼 수 있다.

C는 한계를 나타내는 carrying capacity, k는 성장률이다. 즉, 두 값은 상수로 주어져야 한다. 하지만 만약 이 두 값이 상수가 아니라면 위처럼 수식을 쓰는 것은 불가능하다. 예컨대 페이스북 가입자 수를 population이라고 생각하면, 현재 시점에서 상한은 인터넷에 연결이 가능한 전체 인구 수이지만, 이 수는 시간이 지남에 따라 지속적으로 증가할 것이므로 C는 상수로 나타낼 수 없다. 마찬가지로 성장률 역시 시점에 따라 상이할 것이다.
따라서 C와 k는 상수가 아닌 함수로 표현되어야 하고, 수식은 아래처럼 piecewise logistic growth model로 수정될 수 있다.

위 수식에서 C(t)는 시점에 대한 상한값의 함수로, 해당 도메인 전문가들은 관련 데이터를 확보하고 있기 때문에 C(t) 함수를 쉽게 구할 수 있을 것이다. 반대로 말하면, 도메인 지식 없이는 C(t)를 구할 수 없단 얘기이다. 예를 들어 자사의 주력상품 수요를 예측해야 할 때, 광고, 고객, 타 상품 데이터 등을 활용하면 g(t) 함수를 용이하게 짤 수 있을 것이다.
성장률 역시도 시점에 따른 함수로 표현되어야 한다. a(t) 함수는 성장률을 조정하기 위한 함수이다.
3.1.2 Linear Trend with Changepoints
만약 위 예시와 달리 상한값이 없는 경우라면 간단하게, linear한 방식으로 수식을 만들 수 있다. 아래 식은 위 식의 g(t)의 exponential function에 들어가는 부분을 부호만 바꿔준 것이다.
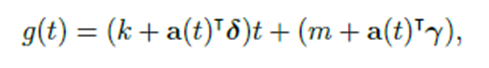
3.2 Seasonality

시계열 데이터는 계절성을 갖기 때문에 계절성을 나타내는 모델링이 필요하다. 시간 변수의 연속성을 살리기 위해 삼각함수 변화를 하듯, 위 같은 fourier series를 활용하여 모델링을 할 수 있다. 위 식에 P는 나타내고 싶은 주기인데, 만약 주간 데이터라면 P=7일 것이고, 연간 데이터라면 P=365.25일 것이다.
만약 β=[a1, b2, … , An, bN]^T라는 행렬과

라는 행렬이 주어지면 S(t)= X(t)*β로 표현된다.
이 때 급수의 항 개수인 N을 무엇으로 정할지가 중요한 대목이다. N의 크기가 커진다면 오버피팅의 위험을 감수해야 하고, N이 너무 작아진다면 언더피팅을 의심해야 하는 trade-off 상황에 놓인다. 주간 데이터에서는 N=3, 연간 데이터에서는 N=10으로 설정하는 것이 가장 성적이 좋았다고 한다.
3.3 Holidays and Events
휴일과 각종 사건들은 시계열에 큰 영향을 미치지만, 이렇다할 계절성을 따르지 않고, 불규칙적이다. 매년 방학이나 한 기업의 연례 행사, 음력을 따르는 각종 공휴일들을 일일이 모델링하는 것이 어려운 작업이다. prophet에서는 각 휴일을 D_i라고 했을 때 아래와 같은 함수를 정의한다.
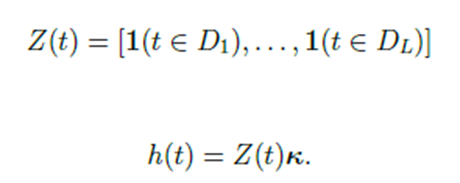
추가적으로 특정 휴일 주변 날도 휴일의 영향력을 받게끔 파라미터를 조정할 수 있다. 예를 들어 크리스마스 이브도 크리스마스의 영향력을 받도록 하고 싶으면 lower_window를 -1로 설정하면 된다.
cf) 한국 holiday 정보는 python의 holidays 패키지에 모두 리스트업이 되어있다고 한다.
3.4 Model fitting
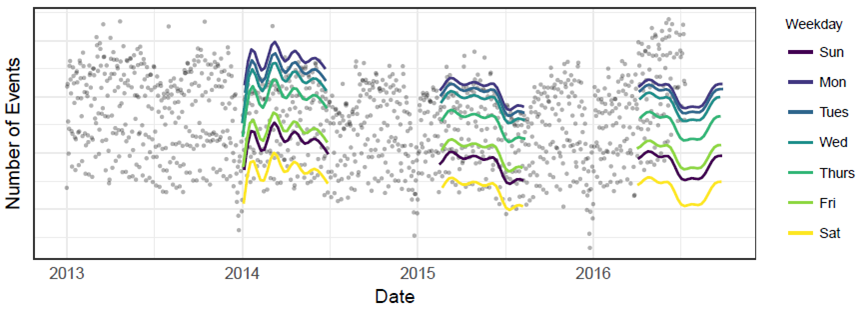
위 그림은 예측시점 전의 일부 데이터만을 갖고 학습을 한 결과이다.

prophet 패키지를 사용하면 위처럼 주기성과 추세 모두 잘 반영한 결과를 낼 수 있다. 앞서 살펴본 auto.arima, ets 등보다 훨씬 매끄러운 예측을 제공한다. 심지어 위 같은 결과물은 아래의 짧은 코드로 작성된 것이다.


위처럼 추세와 계절성이 어떤 영향을 미치는지 그래프로 확인할 수도 있다. 이것 역시 매우 간단한 코드로 출력이 가능하다.
3.5 Analyst-in-the-Loop Modeling
다시 논의의 시작으로 돌아와서, prophet은 시계열 분야에 무지한 분석가가 사용하기 용이한 패키지이다. 그런데 이 때 분석가는 ‘도메인 지식’을 갖고 있는 분석가이다. 따라서 이 도메인 지식을 활용한다면, prophet에서 요구되는 몇 가지 요소의 빈칸을 채울 수 있다.
capacities(시장의 총 규모): 3.1.1에서 언급한 내용이다.
changepoints(상품의 출시 혹은 변화의 시점)
holiday and seasonality(영향력이 큰 휴일 혹은 주기성): 해당 시장에 대해 해박한 전문가는 어떤 날이 프로세스에 영향을 주는지 잘 알 것이다.
smoothing parameter(주기성을 반영할 정도)
paper에선 이러한 정보를 바탕으로 간단한 코드를 짜서 시각화를 하고, 이 시각화를 바탕으로 피드백하여 다양한 시도를 해보기를 권장하고 있다.
4.2. Modeling Forecast Accuracy
예측 결과를 평가하는 방식은 다음과 같다.
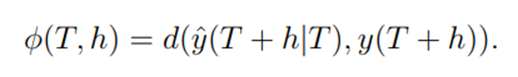
d(y1, y2)는 |y1-y2|를 의미한다. 따라서, 위 수식은 T시점의 데이터가 주어졌을 때, 이후 h기간을 예측할 때의 오차이다. 이 때 발생할 수 있는 오차는 예측 전구간에서 일정하게 발생을 해야 한다.
4.3 Simulated Historical Forecasts
시계열 데이터이므로 cross validation을 사용할 수는 없다. 이 경우 시점이 뒤섞여서 시계열의 가정에 위배되기 때문이다.
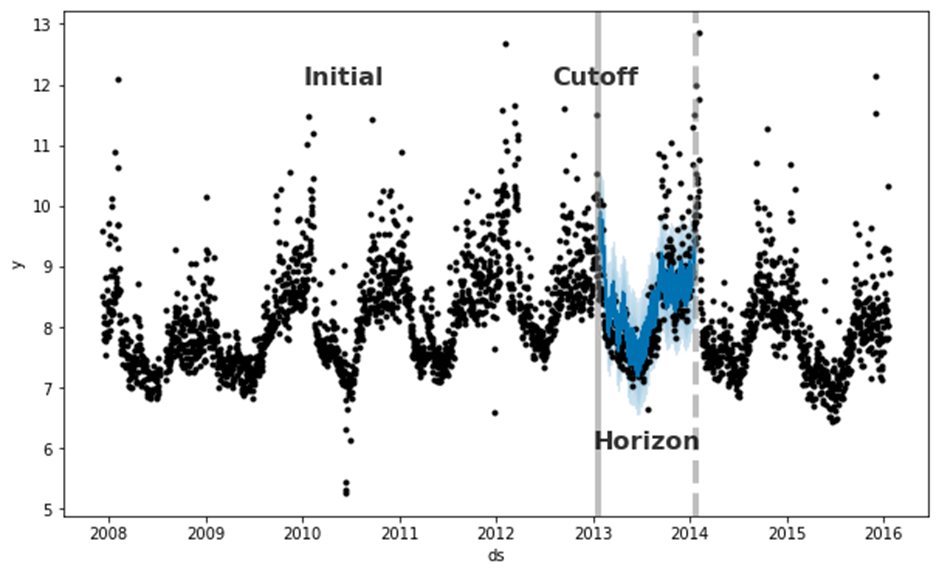
따라서 논문에서는 SHFs(Simulated Historical Forecasts)라는 방식을 사용한다. 이는 initial이라는 초기 학습값을 가지고 period만큼의 기간을 simulating하는 교차검증 방식이다.
'심화 스터디 > 시계열 분석 스터디 (feat.금융)' 카테고리의 다른 글
| 시계열 분석 스터디 2주차(김연규): 전통 시계열 모델 (0) | 2023.05.10 |
|---|---|
| 시계열 분석 스터디 1주차(김연규) (0) | 2023.05.10 |
| 시계열 스터디 5주차(신윤) : Prophet 논문 (0) | 2023.05.04 |
| 시계열 스터디 5주차(우명진) : Prophet 논문 (0) | 2023.05.04 |
| 시계열 스터디 5주차(김태영) : Facebook Prophet (0) | 2023.05.04 |





댓글 영역