고정 헤더 영역
상세 컨텐츠
본문 제목
[논문 리뷰 스터디] Sociomarkers and biomarkers: predictive modeling in identifying pediatric asthma patients at risk of hospital revisits
본문
작성자: 17기 김예은

이 논문은 현재 수강중인 데이터사이언스와 사회학 수업의 신은경 교수님께서 작성한 논문으로 머신러닝을 활용하여 천식환자가 병원에 재방문할 것인지 예측하는 연구이다. 의료데이터를 활용하여 이번 방학 때 배운 랜덤포레스트와 같은 모델링 방법을 사용하였기에 이 논문을 선택해 리뷰해보고자 한다.
Introduction
건강은 생물학적 문제인 만큼 사회적 문제이다.
단순히 질병의 감염적 성질 때문에 병에 걸리는 것이 아니라 사회적 조건이 개인적 측면에 건강 문제에 영향을 준다. 따라서 사회적 요소가 건강 결정요인에 가장 중요한 요소로 인식되고 있을 뿐만 아니라 비유전적 요소가 개인의 건강문제에 약 70% 정도 기여한다고 볼 수 있다. 이 논문에서는 사회적 불평등이 건강불평등으로 어떻게 각인되는지를 설명하기 위해 다양한 사회적 요인들 중 neighborhood level이 key parameter로 지정되었다.
건강의 사회적 결정요인의 중요성에도 불구하고, 임상적 의사결정을 위한 사회적 요인의 적용은 여전히 초기 단계이다.
이 논문은 해마다 천식으로 병원에 재방문하는 환자를 인식할 수 있는 사회적 특징이 무엇이 있는지 알기 위해 biomarkers 와 대응되는 sociomarkers의 개념을 도입하였다. sociomarkers는 사회적 조건의 측정가능한 지표로, 병의 존재를 나타내는 biomarkers와 유사하게 환자가 노출되어 있고, 영향을 받고 있는 요소를 말한다. sociomarkers를 통해 천식 관련 사례로 병원을 재방문할 가능성이 높은 고위험군을 적시에 안정적으로 식별하여 효율적인 건강 감시를 수행한다.
소아 천식 사례로 병원 재방문 가능성을 연구한 이유
1. 천식은 미국에서 가장 흔한 만성 아동기 질환 중 하나
2. 만연한 것 외에도 환경에 대한 민감성으로 인해 주제가 조사 중인 질문과 관련
3. 대부분의 천식 관련 병원 방문은 적절한 예방 치료를 통해 예방 가능

이 논문에서는 환자의 demographic attributes, 환자의 의료 조건을 나타내는 biomarkers, 환자의 사회적 조건을 나타내는 sociomarkers 세 가지 요소를 활용하여 머신러닝 기반 모델을 훈련시킨다. 그리고 소아천식 환자가 병원에 재방문할 확률을 예측할 수 있는 sociomarkers의 타당성과 연관성을 평가하기 위해 결과를 비교한다.

세 종류의 모델
Model 1 - patient-level features of demographics & biomarkers & sociomarkers
Model 2 - patient-level features of demographics & biomarkers
Model 3 - patient-level features of demographics & sociomarkers
Random Forest
개별 트리 모델의 단점

- 계층적 구조로 인해 중간에 에러가 발생하면 다음단계에도 에러 전파
- 적은 개수의 노이즈, 학습 데이터의 미세한 변동에도최종 결과 크게 영향
- 나무의 최종노드 개수를 늘리게 되면 과적합 위험이 있다.
랜덤 포레스트 배경- 앙상블
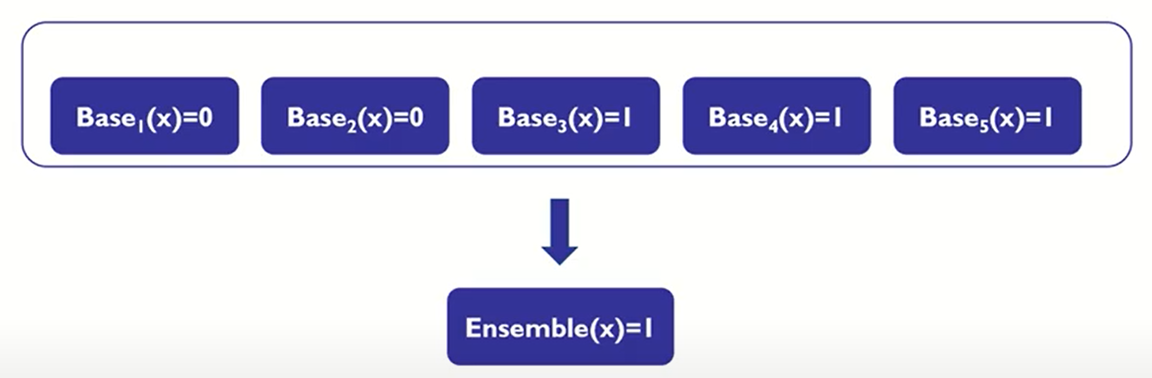
앙상블 모델의 오류율 식은 다음과 같다.


이와 같은 그래프로 앙상블 모델의 오류율을 표현할 수 있다. 앙상블 모델이 base 모델보다 우수한 성능을 보이기 위해서는 base 모델들이 서로 독립적이어야하며, base 모델들의 성능이 무작위 예측을 수행하는 모델보다는 성능이 좋아야한다는 것을 확인할 수 있다.

의사결정나무모델은 앙상블 모델의 base 모델로써 활용도가 높다.
-Low computational complexity: 데이터 크기가 방대해도 모델 구축 빠름
-Nonparametric: 데이터 분포에 대한 전제가 따로 필요 X
랜덤 포레스트란?
-다수의 의사결정나무모델에 의한 예측을 종합하는 앙상블 방법으로 관측치 수에 비해 변수의 수가 많은 고차원의 데이터에서 중요 변수 선택 기법으로 널리 활용되고 있다.

1. Bootstrap 기법으로 다수의 training data 생성
2. 무작위 변수 사용해 training data로 decision tree 모델을 구축
3. 예측 종합
Bagging(Bootstrap Aggregating) - 여러 개의 training data 생성해 데이터마다 개별 의사결정나무 모델을 구축

Bootstrap
-각 데이터셋은 복원 추출을 통해 원래 데이터 수만큼의 크기를 갖도록 샘플링하는 과정



Random Subspace - 의사결정나무 모델 구축 시 변수를 무작위로 선택

- 원래 변수등 중 모델 구축에 쓰인 입력 변수를 무작위 선택
- 선택된 입력 변수 중 분할된 변수 선택
- 이러한 과정은 full-grown tree가 될 때까지 반복
Random Forest 의 Error
- 각각의 개별 tree는 과적합될 수 있음
- tree가 충분히 많으면 Strong Law of Large Numbers에 의해 과적합 되지 않고 에러는 limiting value에 수렴하게 됨.

-Decision tree 사이의 평균 상관관계
- 올바로 예측한 tree와 잘못 예측한 tree수 차이의 평균
Bagging 과 random subspace 기법은 각 모델들의 독립성, 일반화, 무작위성을 최대화 하여 모델간의 상관관계를 감소시킴.
랜덤포레스트는 간접적인 방식으로 변수의 중요도를 결정한다.
1. 원래 데이터 집합에 대해 Out of bag Error를 구한다.
2. 특정 변수의 값을 임의로 뒤섞은 데이터 집합에 대해 OOB Error를 구한다.
3. 개별 변수의 중요도는 2단계와 1단계 OOB Error 차이의 평균과 분산을 고려하여 결정한다.
Results










댓글 영역