고정 헤더 영역
상세 컨텐츠
본문
Hyper Text Transfer Protocol
- 웹에서 이루어지는 모든 데이터 교환의 기초이며, 서버-클라이언트 프로토콜이기도 하다.
- 서버-클라이언트 프로토콜 : 수신자(웹 브라우저) 측에 의해 요청request이 초기화되는 프로토콜을 의미한다.
- HTML 문서와 같은 리소스들을 가져올 수 있는 프로토콜
1. 개요
하나의 완전한 문서는 텍스트, 레이아웃 설명, 이미지, 비디오, 스크립트 등 불러온(fetched) 하위 문서들로 재구됩니다. 클라이언트와 서버들은 (데이터 스트림과 대조적으로) 개별적인 메시지 교환에 의해 통신합니다.
보통 브라우저인 클라이언트에 의해 전송되는 메시지를 요청(requests)이라고 부르며, 그에 대해 서버에서 응답으로 전송되는 메시지를 응답(responses)이라고 부릅니다.
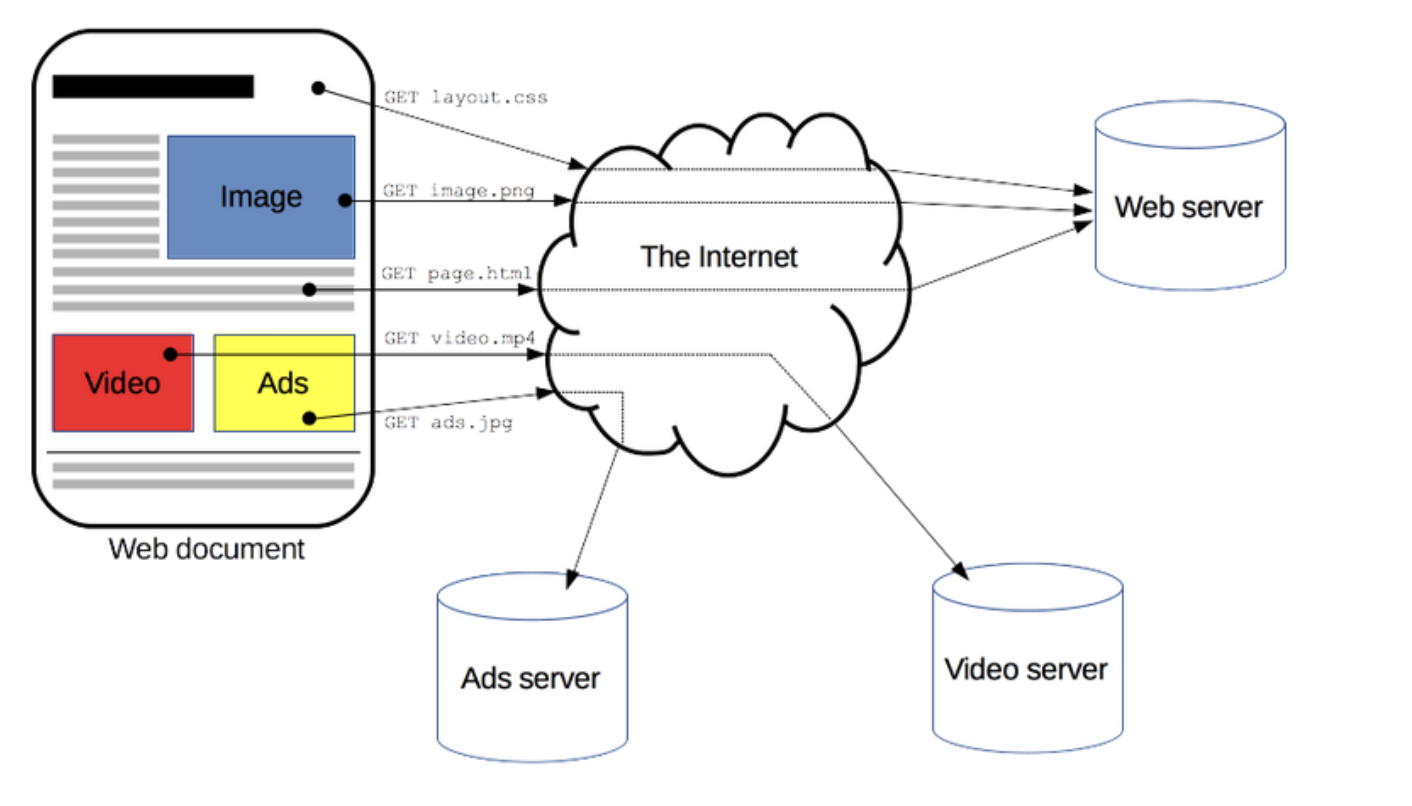
2. HTTP 기반 시스템의 구성요소
요청은 하나의 개체, 사용자 에이전트(또는 그것을 대신하는 프록시)에 의해 전송됩니다. 대부분의 경우, 사용자 에이전트는 브라우저입니다.
각각의 개별적인 요청들은 서버로 보내지며, 서버는 요청을 처리하고 응답을 제공합니다. 이 요청과 응답 사이에는 여러 개체들이 있는데, 예를 들면 다양한 작업을 수행하는 게이트웨이 또는 캐시 역할을 하는 프록시 등이 있습니다.
실제로는 브라우저와 요청을 처리하는 서버 사이에는 좀 더 많은 컴퓨터들이 존재합니다: 라우터, 모뎀 등이 있죠. 웹의 계층적인 설계 덕분에, 이들은 네트워크와 전송 계층 내로 숨겨집니다.

Client: 사용자 에이전트
사용자 에이전트는 사용자를 대신하여 동작하는 모든 도구입니다. 이 역할은 주로 브라우저에 의해 수행됩니다. 브라우저는 항상 요청을 보내는 개체이므로 결코 서버가 될 수 없습니다.
서버에 요청하는 클라이언트 소프트웨어(IE, Chrome, Firefox, Safari ...)가 설치된 컴퓨터를 이용합니다. 클라이언트는 URI를 이용해서 서버에 접속하고, 데이터를 요청합니다.
URL; 서버에 자원을 요청하기 위해 입력하는 영문 주소이다.
- 웹 페이지를 표시하기 위해,
- 브라우저는 페이지의 HTML 문서를 가져오기 위한 요청을 전송한 뒤,
- 파일을 구문 분석하여 실행해야 할 스크립트 그리고 레이아웃 정보(CSS)에 대응하는 추가적인 요청들을 가져옵니다.
- 브라우저는 완전한 문서인 웹 페이지를 표시하기 위해 그런 리소스들을 혼합합니다.
- 브라우저에 의해 실행된 스크립트는 이후 단계에서 좀 더 많은 리소스들을 가져올 수 있으며 브라우저는 그에 따라 웹 페이지를 갱신하게 됩니다.
웹 페이지; 하이퍼텍스트 문서로, 표시된 텍스트의 일부는 사용자가 사용자 에이전트를 제어하고 웹을 돌아다닐 수 있도록 새로운 웹 페이지를 가져오기 위해 실행될 수 있는 링크
Server
통신 채널의 반대편에는 클라이언트가 요청한 문서를 제공하는 서버가 있습니다.
클라이언트의 요청을 받아서, 요청을 해석하고 응답을 하는 소프트웨어가 설치된 컴퓨터(Apache, nginx, IIS, lighttpd) 등이 서버 소프트웨어입니다. 웹 서버는 보통 표준포트인 80번 포트를 사용합니다.
Proxy
웹 브라우저와 서버 사이에서는 수많은 컴퓨터와 머신이 HTTP 메시지를 이어 받고 전달합니다. 여러 계층으로 이루어진 웹 스택 구조에서 대부분은 전송, 네트워크 혹은 물리 계층(~L4)에서 동작하며, 성능에 상당히 큰 영향을 주지만 HTTP 계층에서는 이들이 어떻게 동작하는지 눈에 보이지 않습니다.
이러한 컴퓨터/머신 중에서도 애플리케이션 계층에서 동작하는 것들을 일반적으로 프록시라고 부릅니다. 프록시는 눈에 보이거나 그렇지 않을 수도 있으며(프록시를 통해 요청이 변경되거나 변경되지 않을 수도 있다.) 다양한 기능들을 수행할 수 있습니다:
3. HTTP 특징
HTTP는 사람이 읽을 수 있으며 간단하게 고안되었습니다. 심지어 HTTP/2가 다소 더 복잡해졌지만 여전히 HTTP 메세지를 프레임별로 캡슐화하여 간결함을 유지하였습니다. HTTP 메시지들은 사람이 읽고 이해할 수 있어, 테스트하기 쉽고 초심자의 진입장벽을 낮췄습니다.
HTTP/1.0에서 소개된, HTTP 헤더는 HTTP를 확장하고 실험하기 쉽게 만들어주었습니다. 클라이언트와 서버가 새로운 헤더의 시맨틱에 대해 간단한 합의만 한다면, 언제든지 새로운 기능을 추가할 수 있습니다.
Stateless & Connectionless

HTTP는 Connectionless 방식으로 작동한다. 서버에 연결하고, 요청해서 응답을 받으면 연결을 끊어버린다. 기본적으로는 자원 하나에 대해서 하나의 연결을 만든다.

연결을 끊어버리기 때문에, 클라이언트의 이전 상태를 알 수가 없다. 이러한 HTTP의 특징을 stateless라고 하는데, Connectionless 로 부터 파생되는 특징이라고 할 수 있다.
데이터를 주고 받기 위한 각각의 데이터 요청이 서로 독립적으로 관리가 된다. 즉, 이전 데이터 요청과 다음 데이터 요청이 서로 관련이 없다. 이러한 특징 덕에 서버는 세션과 같은 별도의 추가 정보를 관리하지 않아도 되고, 다수의 요청 처리 및 서버의 부하를 줄일 수 있는 성능 상의 이점이 생긴다.
클라이언트의 이전 상태 정보를 알 수 없게 되면, 웹 서비스를 하는데 당장에 문제가 생긴다. 클라이언트가 과거에 로그인을 성공하더라도 로그 정보를 유지할 수가 없다. HTTP는 cookie를 이용해서 이 문제를 해결하고 있다.
Cookie; 클라이언트와 서버의 상태 정보를 담고 있는 정보조각
예를 들어, 동일한 연결 상에서 연속하여 전달된 두 개의 요청 사이에는 연결고리가 없습니다. 하지만 e-커머스 쇼핑 바구니처럼, 일관된 방식으로 사용자가 페이지와 상호작용하길 원할 때 문제가 됩니다.
HTTP의 핵심은 상태가 없는 것이지만 HTTP 쿠키는 상태가 있는 세션을 만들도록 해줍니다. 헤더 확장성을 사용하여, 동일한 컨텍스트 또는 동일한 상태를 공유하기 위해 각각의 요청들에 세션을 만들도록 HTTP 쿠키가 추가됩니다.
- 예시두번째 요청 시 : 클라이언트가 서버에게 요청(cookie)하면 서버는 cookie를 key로 자신의 DB 조회한 후 로그인여부 확인
- 첫 요청 시 : 클라이언트 로그인 성공하면, 서버 로그인정보를 자신의 DB에 저장한다. (서버는 cookie를 key로하는 값을 데이터베이스에 저장하는 방식으로 "세션"을 유지한다) 그 후 클라이언트에게 해당 cookie를 준다. 클라이언트는 다음 번 요청때 cookie를 서버에 보내는데, 서버는 cookie 값으로 자신의 데이터베이스를 조회해서 로그인 여부를 확인할 수 있다.
연결은 전송 계층(L4)에서 제어되므로 근본적으로 HTTP 영역 밖입니다.
HTTP는 연결될 수 있도록 하는 근본적인 전송 프로토콜을 요구하지 않습니다; 다만 그저 신뢰할 수 있거나 메시지 손실이 없는(최소한의 오류는 표시) 연결을 요구할 뿐입니다. 인터넷 상의 가장 일반적인 두 개의 전송 프로토콜 중에서 TCP는 신뢰할 수 있으며 UDP는 그렇지 않습니다. 그러므로 HTTP는 연결이 필수는 아니지만 연결 기반인 TCP 표준에 의존합니다.
- 클라이언트와 서버가 HTTP를 요청/응답으로 교환하기 전에 여러 왕복이 필요한 프로세스인 TCP 연결을 설정해야 합니다.
- HTTP/1.0의 기본 동작은 각 요청/응답에 대해 별도의 TCP 연결을 여는 것입니다. 이 동작은 여러 요청을 연속해서 보내는 경우에는 단일 TCP 연결을 공유하는 것보다 효율적이지 못합니다. 이러한 결함을 개선하기 위해, HTTP/1.1은 (구현하기 어렵다고 입증된) 파이프라이닝 개념과 지속적인 연결의 개념을 도입했습니다. HTTP/2는 연결을 좀 더 지속되고 효율적으로 유지하는데 도움이 되도록, 단일 연결 상에서 메시지를 다중 전송(multiplex)하여 한 걸음 더 나아갔습니다.
4. HTTP로 제어
캐시
HTTP로 문서가 캐시되는 방식을 제어할 수 있다. 서버는 캐시 대상과 기간을 프록시와 클라이언트에 지시할 수 있고, 클라이언트는 지정된 문서를 무시하라고 중간 캐시 프록시에게 지시할 수 있다.
세션
쿠키 사용은 서버 상태를 요청과 연결하도록 해준다. 이것은 HTTP가 기본적으로 상태없는stateless 프로토콜임에도 세션을 만들어주는 계기가 된다.
5. HTTP 흐름
클라이언트가 서버와 통신하는 과정은 다음과 같다.
(1) TCP 연결을 연다.
TCP 연결은 요청을 보내거나 응답을 받는데 사용된다. 클라이언트는 새 연결을 열거나, 기존 연결을 재사용하거나, 서버에 대한 여러 TCP 연결을 열 수 있다.
(2) 서버에게 HTTP 메시지를 전송한다.
GET / HTTP/1.1
Host: [developer.mozilla.org](<http://developer.mozilla.org/>)
Accept-Language: fr
(3) 서버가 전송한 응답을 읽어들인다.
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
(4) 연결을 닫거나 다른 요청들을 위해 재사용한다.
6. HTTP 메시지
요청 Request

- 요청 메서드Medthod
- GET : 존재하는 자원에 대한 요청
- POST : 새로운 자원을 생성
- PUT : 존재하는 자원에 대한 변경
- DELETE : 존재하는 자원에 대한 삭제
- Path : 가져오려는 리소스의 경로
- Version of the protocol : HTTP 프로토콜의 버전
- header : 서버에 대한 추가 정보를 전달
응답 Response
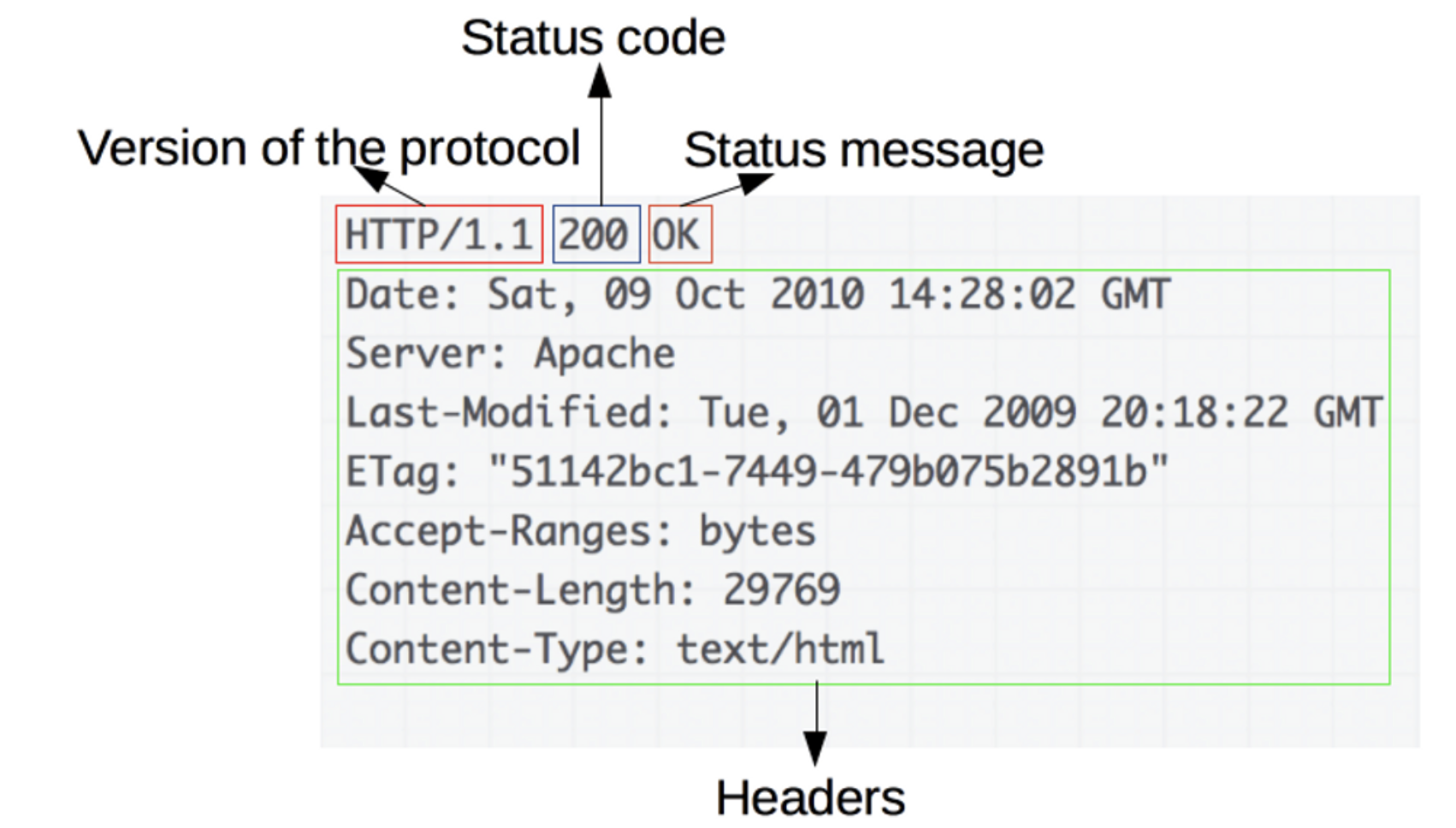
(HTTP) Status code; 요청의 성공 여부와, 그 이유를 나타낸다.
URL과 요청 메서드가 클라이언트에서 설정해야 하는 정보라면, HTTP 상태코드는 서버에서 설정해주는 응답 정보이다.
200번대의 상태 코드는 대부분 성공을 의미합니다.
- 200 : GET 요청에 대한 성공
- 204 : No Content. 성공했으나 응답 본문에 데이터가 없음
- 205 : Reset Content. 성공했으나 클라이언트의 화면을 새로 고침하도록 권고
- 206 : Partial Conent. 성공했으나 일부 범위의 데이터만 반환
300번대의 상태 코드는 대부분 클라이언트가 이전 주소로 데이터를 요청하여 서버에서 새 URL로 리다이렉트를 유도하는 경우입니다.
- 301 : Moved Permanently, 요청한 자원이 새 URL에 존재
- 303 : See Other, 요청한 자원이 임시 주소에 존재
- 304 : Not Modified, 요청한 자원이 변경되지 않았으므로 클라이언트에서 캐싱된 자원을 사용하도록 권고.
400번대 상태 코드는 대부분 클라이언트의 코드가 잘못된 경우입니다. 유효하지 않은 자원을 요청했거나 요청이나 권한이 잘못된 경우 발생합니다.
- 400 : Bad Request, 잘못된 요청
- 401 : Unauthorized, 권한 없이 요청. Authorization 헤더가 잘못된 경우
- 403 : Forbidden, 서버에서 해당 자원에 대해 접근 금지
- 404 : Not Found, 요청한 자원이 서버에 없음을 의미
- 405 : Method Not Allowed, 허용되지 않은 요청 메서드
- 409 : Conflict, 최신 자원이 아닌데 업데이트하는 경우. ex) 파일 업로드 시 버전 충돌
500번대 상태 코드는 서버 쪽에서 오류가 난 경우입니다.
- 501 : Not Implemented, 요청한 동작에 대해 서버가 수행할 수 없는 경우
- 503 : Service Unavailable, 서버가 과부하 또는 유지 보수로 내려간 경우
Hyper Text Transfer Protocol Secure
HTTP에 데이터 암호화가 추가된 프로토콜이다. HTTPS는 HTTP와 다르게 443번 포트를 사용하며, 네트워크 상에서 중간에 제3자가 정보를 볼 수 없도록 암호화를 지원하고 있다.
1. 대칭키 암호화와 비대칭키 암호화
HTTPS는 대칭키 암호화 방식과 비대칭키 암호화 방식을 모두 사용하고 있다.
- 대칭키 암호화키가 노출되면 매우 위험하지만 연산 속도가 빠름
- 클라이언트와 서버가 동일한 키를 사용해 암호화/복호화를 진행함
- 비대칭키(공개키) 암호화키가 노출되어도 비교적 안전하지만 연산 속도가 느림
- 1개의 쌍으로 구성된 공개키와 개인키를 암호화/복호화 하는데 사용함
대칭키는 비교적 쉬운 개념이므로, 비대칭키 암호화에 대해 조금 자세히 살펴보도록 하자.
비대칭키 암호화는 공개키/개인키 암호화 방식을 이용해 데이터를 암호화하고 있다. 공개키와 개인키는 서로를 위한 1쌍의 키이다.
공개키; 모두에게 공개가능한 키 개인키; 나만 가지고 알고 있어야 하는 키
암호화를 공개키로 하느냐 개인키로 하느냐에 따라 얻는 효과가 다른데, 공개키와 개인키로 암호화하면 각각 다음과 같은 효과를 얻을 수 있다.
- 공개키 암호화 공개키로 암호화를 하면 개인키로만 복호화할 수 있다. -> 개인키는 나만 가지고 있으므로, 나만 볼 수 있다.
- 개인키 암호화 개인키로 암호화하면 공개키로만 복호화할 수 있다. -> 공개키는 모두에게 공개되어 있으므로, 내가 인증한 정보임을 알려 신뢰성을 보장할 수 있다.

이러한 SSL 방식을 적용하려면 인증서를 발급받아 서버에 적용시켜야 한다. 인증서는 사용자가 접속한 서버가 우리가 의도한 서버가 맞는지를 보장하는 역할을 한다. 인증서를 발급하는 기관을 CA(Certificate Authority)라고 부른다.
2. HTTPS의 동작 과정
HTTPS는 대칭키 암호화와 비대칭키 암호화를 모두 사용하여 빠른 연산 속도와 안정성을 모두 얻고 있다.
HTTPS 연결 과정(Hand-Shaking)에서는 먼저 서버와 클라이언트 간에 세션키를 교환한다. 여기서 세션키는 주고 받는 데이터를 암호화하기 위해 사용되는 대칭키이며, 데이터 간의 교환에는 빠른 연산 속도가 필요하므로 세션키는 대칭키로 만들어진다.
문제는 이 세션키를 클라이언트와 서버가 어떻게 교환할 것이냐 인데, 이 과정에서 비대칭키가 사용된다.
즉, 처음 연결을 성립하여 안전하게 세션키를 공유하는 과정에서 비대칭키가 사용되는 것이고, 이후에 데이터를 교환하는 과정에서 빠른 연산 속도를 위해 대칭키가 사용되는 것이다.
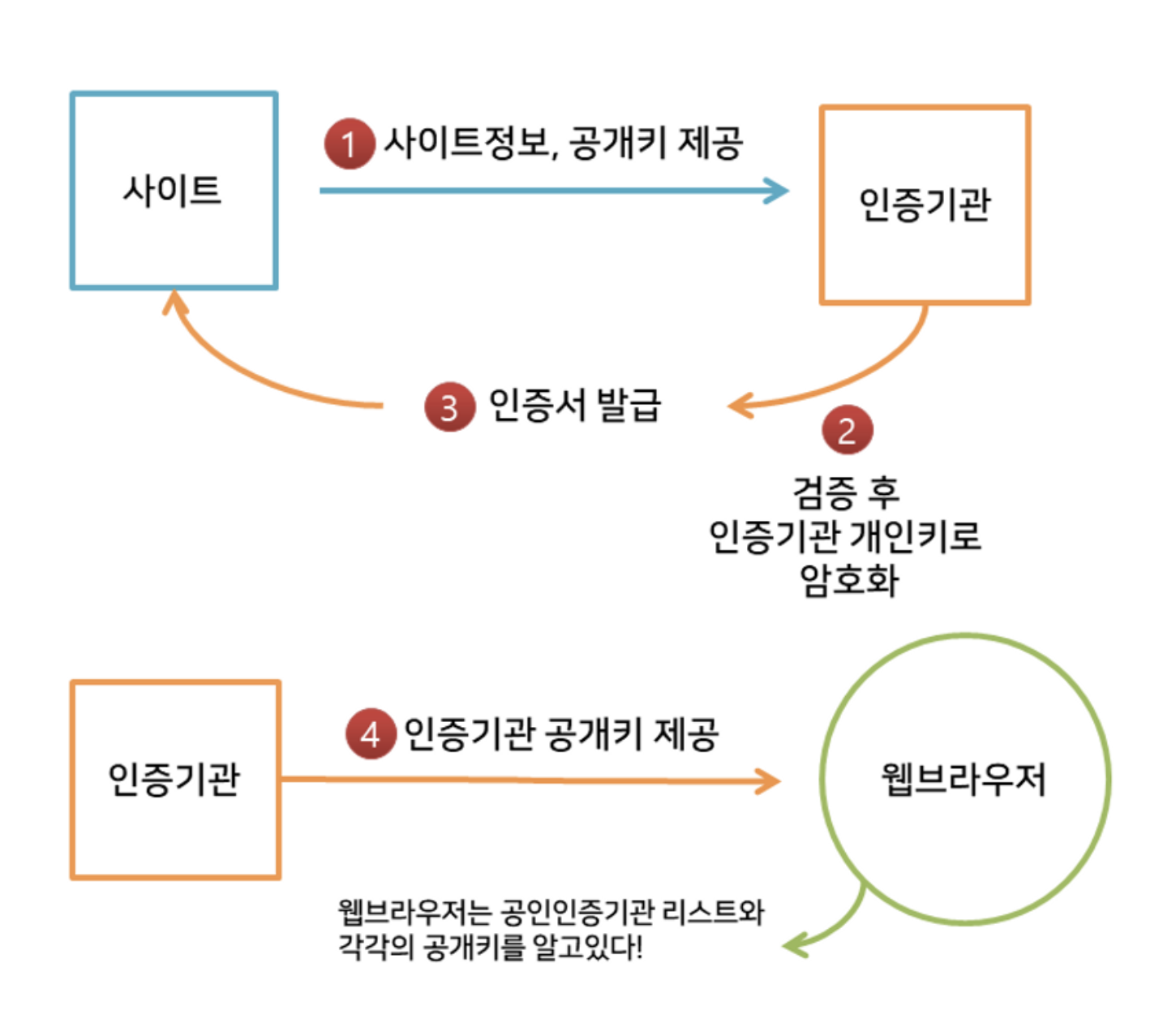
- 서버(사이트)는 공개키와 개인키를 만들고, 신뢰할 수 있는 인증기관CA에 자신의 정보와 공개키를 제공한다.
- CA는 서버가 제출한 데이터를 검증하고, CA의 개인키로 이를 암호화한다.
- CA는 서버에게 인증서를 준다.
- CA는 웹 브라우저(클라이언트)에게 자신의 공개키를 제공한다.
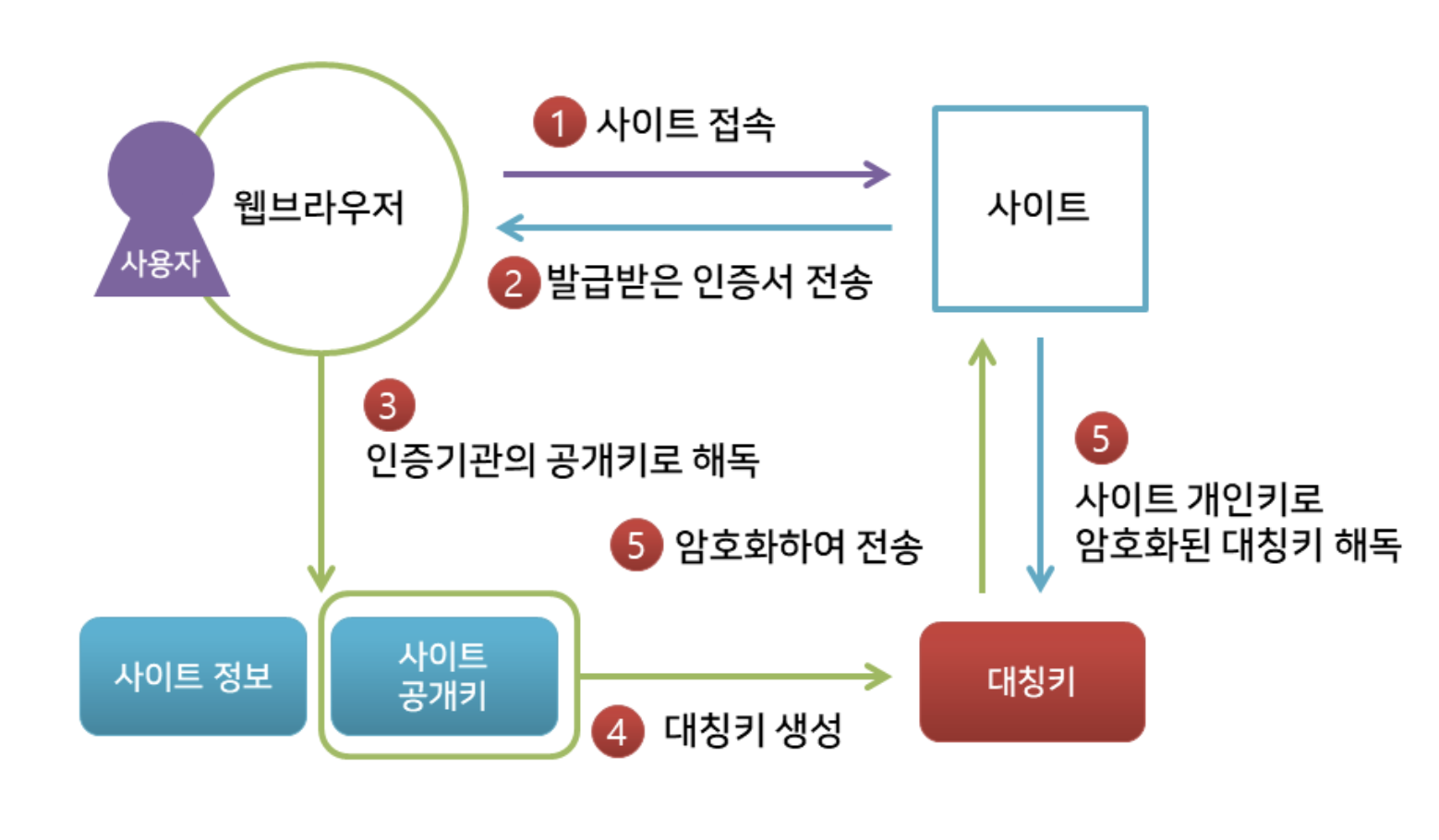
- 클라이언트가 사이트에 접속한다.
- 서버는 자신의 인증서를 브라우저에게 준다.
- 브라우저는 앞서 미리 받았던 CA의 공개키로 인증서를 해독하여 검증한다. 이 과정을 통해 사이트의 정보와 서버의 공개키를 얻는다.
- 인증서의 유효성을 검사하고 대칭키(세션키)를 발급한다.
- 브라우저는 서버의 공개키로 대칭키(세션키)를 암호화해서 다시 사이트로 보낸다.
- 사이트는 개인키로 암호문을 해독하여 대칭키(세션키)를 얻게 되고, 이제 대칭키로 데이터를 주고 받을 수 있다.

클라이언트와 서버는 동일한 대칭키(세션키)를 공유하므로 데이터를 전달할 때 세션키로 암호화/복호화를 진행한다.
3. HTTPS의 발급 과정
서버는 클라이언트와 세션키를 공유하기 위한 공개키를 생성해야 하는데, CA에 공개키를 전송하여 인증서를 발급받는다.
- A 기업은 HTTP 기반의 애플리케이션에 HTTPS를 적용하기 위해 공개키/개인키를 발급한다.
- CA 기업에게 공개키를 저장하는 인증서의 발급을 요청한다.
- CA 기업은 인증서를 생성하고, CA 기업의 개인키로 암호화하여 A 기업에게 이를 제공한다.
- A기업은 클라이언트에게 암호화된 인증서를 제공한다.
- 브라우저(클라이언트)는 CA 기업의 공개키를 미리 다운받아 갖고 있어, 암호화된 인증서를 복호화한다.
- 암호화된 인증서를 복호화하여 얻은 A 기업의 공개키로 세션키를 공유한다.
인증서는 CA의 개인키로 암호화되었기 때문에, 신뢰성을 확보할 수 있고, 클라이언트는 A 기업의 공개키로 데이터를 암호화하였기 때문에 A기업만 복호화하여 원본의 데이터를 얻을 수 있다.
여기서 인증서에는 A 기업의 공개키가 포함있다. 또한 브라우저에는 인증된 CA 기관의 정보들이 사전에 등록되어 있어 인증된 CA 기관의 인증서가 아닐 경우에는 다음과 같은 형태로 브라우저에서 보여지게 된다.
'심화 스터디 > 데이터 엔지니어링 스터디' 카테고리의 다른 글
| [2.5차/15기 김제성] API & REST API (0) | 2023.03.23 |
|---|---|
| [2차시/15기 이병주] REST API 와 GraphQL (0) | 2023.03.23 |
| [1.5차시/15기 이병주] TCP/IP (0) | 2023.03.23 |
| [1.5차시/16기 박민규] TCP/IP (0) | 2023.03.22 |
| [1차시/16기 박민규] OSI 7계층 (0) | 2023.03.22 |





댓글 영역